序祯达生物联合创始人兼CIO费家俊:弹性计算助力测序多组学应用提升新药研发效率[阿里云]
2023年10月31日-11月2日,2023云栖大会在中国杭州·云栖小镇举行,序祯达生物联合创始人兼首席信息官费家俊在【高性能计算】专场中带来了题为《加速裂变,催化创新——弹性计算赋能测序多组学应用提升新药研发效率》的主题演讲,围绕弹性计算如何助力测序多组学应用提升新药研发效率、创新药研发详解以及测序分析等相关话题展开。以下是费家俊的演讲内容整理,供阅览。 图:序祯达生物联合创始人兼首席信息官 费家俊
图:序祯达生物联合创始人兼首席信息官 费家俊
今天主要讲述在基因测序的多组学、生命科学的研究领域,如何使用阿里云高性能计算的技术。序祯达生物是一家服务于科研机构、诊断公司、大学或者制药企业的科研服平台,基因测序是一个比较小市场中比较专业的一种服务,这种服务跟每一个人的生活、整个社会医药行业的发展是息息相关的,因为几乎国内所有的原研药或者新药研发的项目几乎都有合作,会从早期的药物靶点发现到临床实验,一直到后期的回顾性研究等等,在这样一些领域当中,为客户去提供相关的组学服务,甚至是每天吃的东西,都是通过人工培育育种出来的,育种领域的基因测序也承担了非常大量的测序工作,跟每个人都会有点关系。序祯达生物的总部在上海的外高桥,一直以来是做以高通量测序为核心的多组学研发技术的服务平台,下图中展示了很多高价值的仪器设备,这些仪器设备每天运行过程中都是在产生数据,这些产生出来的数据要用阿里云平台来进行处理。 与此同时,整个实验室可能是目前国内整行业里面整个指控体系标准最高的一个实验室,已荣获CLIA 、CAP、ISO15189、ISO27001国际高标准的四重权威认证,承接了非常多的样本。通过分布式实验室的尝试以及与阿里云高性能计算平台的对接,使医药研发的整个生命周期能够缩短,大大降低了医药研发的成本。
与此同时,整个实验室可能是目前国内整行业里面整个指控体系标准最高的一个实验室,已荣获CLIA 、CAP、ISO15189、ISO27001国际高标准的四重权威认证,承接了非常多的样本。通过分布式实验室的尝试以及与阿里云高性能计算平台的对接,使医药研发的整个生命周期能够缩短,大大降低了医药研发的成本。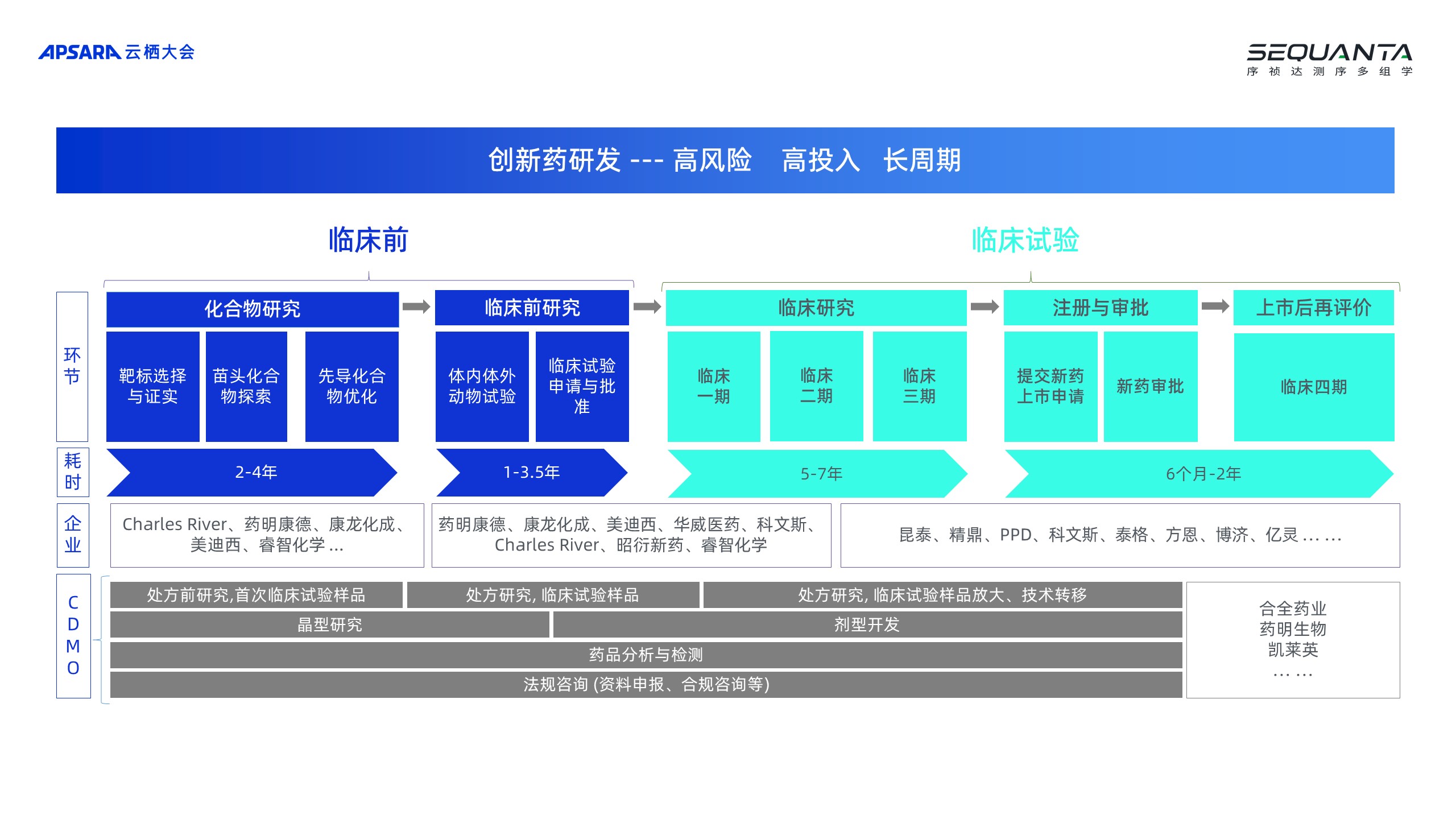 生命科学和医药研发行业会涉及到很高的成本、很大的投入,以至于大家会听说一个药,要花几十亿、上百亿的研发资金。目前,整个医药研发行业的全生命周期从头到尾的过程,可以持续十年的时间,这个过程非常长,主要分为临床前和临床试验。临床前研究:这个主要是在实验室里去研究疾病成因、相关的蛋白质靶点以及用什么样的化合物结合,这些化合物有没有毒性、能不能代谢、能不能成药,能不能传递到一些肿瘤相关的一些位置上面,这些事情叫做临床前的研究。临床实验:等到一个化合物有了好的苗头,在临床前的研究拿到一个比较好的结果后,就能进入临床后的实验。临床后的实验与患者相关,临床的一期、二期、三期,整个周期和过程是非常漫长的,行业中有非常多的参与者在这个过程提供相关的业务服务。二、测序行业的特点:资产密集型、算力密集型运用测序和多组学的技术是能够在非常大的技术层面去提供一个更加快捷和直观的结果,这个过程与看地球以前是二维、三维,现在变成四维更多的传感器一样的道理,以前看一个疾病的时候,通常只是通过表征去看,或者是通过单一的组学,比如基因组学给患者测序。
生命科学和医药研发行业会涉及到很高的成本、很大的投入,以至于大家会听说一个药,要花几十亿、上百亿的研发资金。目前,整个医药研发行业的全生命周期从头到尾的过程,可以持续十年的时间,这个过程非常长,主要分为临床前和临床试验。临床前研究:这个主要是在实验室里去研究疾病成因、相关的蛋白质靶点以及用什么样的化合物结合,这些化合物有没有毒性、能不能代谢、能不能成药,能不能传递到一些肿瘤相关的一些位置上面,这些事情叫做临床前的研究。临床实验:等到一个化合物有了好的苗头,在临床前的研究拿到一个比较好的结果后,就能进入临床后的实验。临床后的实验与患者相关,临床的一期、二期、三期,整个周期和过程是非常漫长的,行业中有非常多的参与者在这个过程提供相关的业务服务。二、测序行业的特点:资产密集型、算力密集型运用测序和多组学的技术是能够在非常大的技术层面去提供一个更加快捷和直观的结果,这个过程与看地球以前是二维、三维,现在变成四维更多的传感器一样的道理,以前看一个疾病的时候,通常只是通过表征去看,或者是通过单一的组学,比如基因组学给患者测序。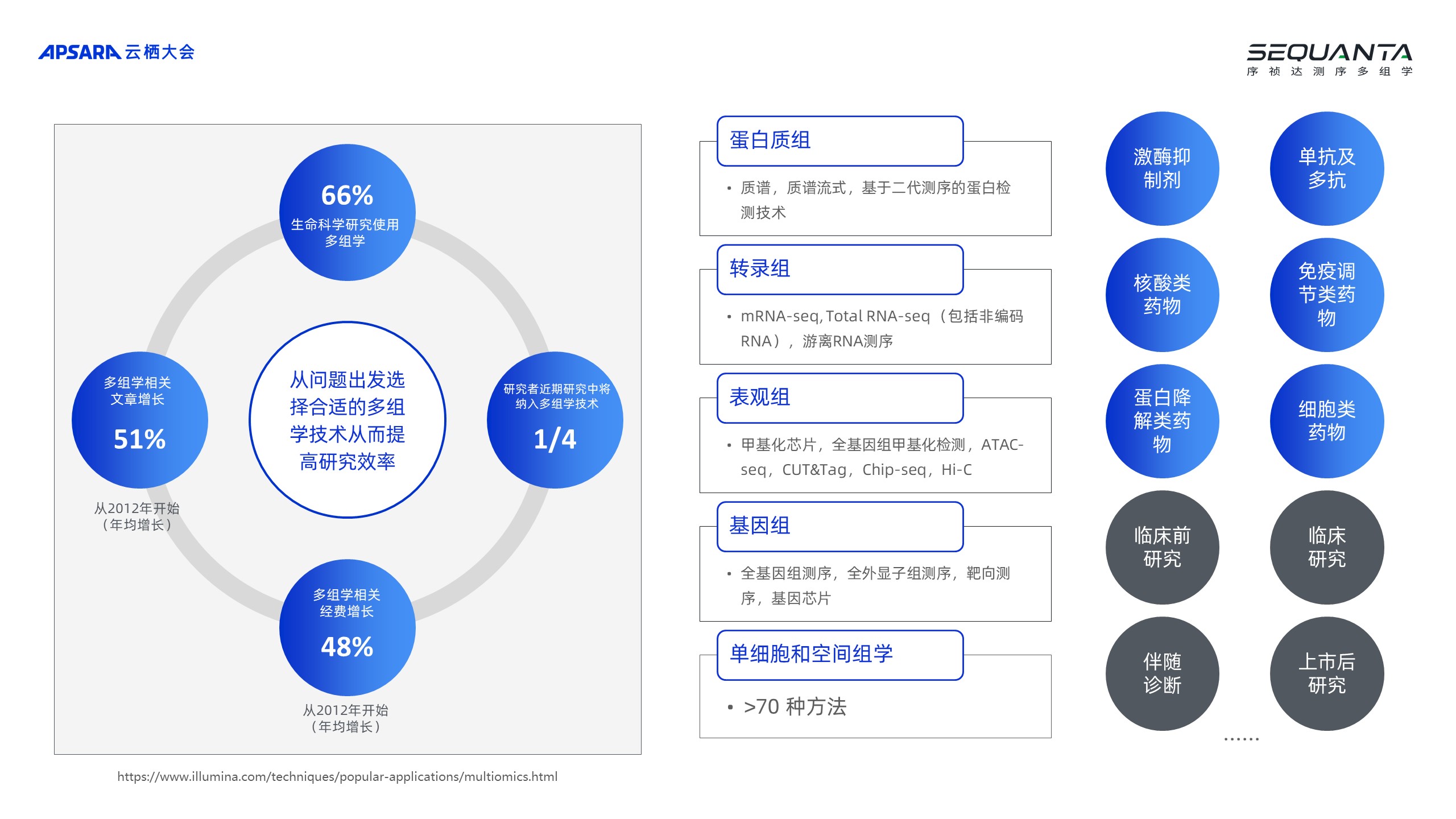 目前,在疾病的研究领域已经用到了更多的分析方法,这些分析方法是近十几年建立起来的,把这些分析方法叠加在一起使用是近几年的事,通过叠加实验的结果能得出非常好的观察。
目前,在疾病的研究领域已经用到了更多的分析方法,这些分析方法是近十几年建立起来的,把这些分析方法叠加在一起使用是近几年的事,通过叠加实验的结果能得出非常好的观察。 上图的观察是在2018年、2019年到2020年这几年时间帮助一家企业做了食管鳞癌的队列,这个队列像以前去研究一个疾病的时候,通常只是从肿瘤细胞显微镜下的结果去做一些相关的分析或者给患者做一些测序,通过基因一些位点上的突变得出结论,在做食管鳞癌研究的时候植入了多组学的概念,把蛋白质组学引入到整个的研究当中,不只是去测患者的基因,也去测相关的代谢产物以及蛋白质。后期,又加入了免疫的一些因素,去研究免疫环境的一些变化,因此就得到了一个非常好的结果,相当于把一个疾病通过更丰富、更加立体的数据拼装一套数据,呈现一个立体的结果。我相信大家应该听过有很多关于生命科学领域计算方面的一些研究,比如蛋白质的预测或者基因分析的解读,最后要把它们拼装起来,去根本性地回答一个疾病是怎么产生的,以及用什么样的可能性去找到跟它结合的位点,找到一些相关的化合物。
上图的观察是在2018年、2019年到2020年这几年时间帮助一家企业做了食管鳞癌的队列,这个队列像以前去研究一个疾病的时候,通常只是从肿瘤细胞显微镜下的结果去做一些相关的分析或者给患者做一些测序,通过基因一些位点上的突变得出结论,在做食管鳞癌研究的时候植入了多组学的概念,把蛋白质组学引入到整个的研究当中,不只是去测患者的基因,也去测相关的代谢产物以及蛋白质。后期,又加入了免疫的一些因素,去研究免疫环境的一些变化,因此就得到了一个非常好的结果,相当于把一个疾病通过更丰富、更加立体的数据拼装一套数据,呈现一个立体的结果。我相信大家应该听过有很多关于生命科学领域计算方面的一些研究,比如蛋白质的预测或者基因分析的解读,最后要把它们拼装起来,去根本性地回答一个疾病是怎么产生的,以及用什么样的可能性去找到跟它结合的位点,找到一些相关的化合物。 目前,在做一些研究面临的一个挑战——需要的仪器设备非常多,这是一个资产密集型的行业,也是一个知识密集型的行业。比如,公司研究生以上的学历是65%,同时也是算力密集型的行业,因此直接造成结果是整个医药研发的成本非常高,周期非常长。最近,有一些非常不错的公司在国内帮助海外的药厂去做研发外包的流程,也是医药领域非常火热的一条赛道。分子生物学当中有中心法则,所有的蛋白质是由一个 RNA 翻译而来的,RNA 又是从 DNA 转录而来,我们研究的是细胞当中的 DNA 每一个位点上、每一位的碱基对读出来是什么样的结果,是A、T、C还是 G ——这个过程叫做测序,就是把细胞的细胞核打开,然后把染色体拉直,通过仪器读取出它里面双螺旋中每一位上面的碱基对,因此这是一个非常微观世界中的巨大数据积累。
目前,在做一些研究面临的一个挑战——需要的仪器设备非常多,这是一个资产密集型的行业,也是一个知识密集型的行业。比如,公司研究生以上的学历是65%,同时也是算力密集型的行业,因此直接造成结果是整个医药研发的成本非常高,周期非常长。最近,有一些非常不错的公司在国内帮助海外的药厂去做研发外包的流程,也是医药领域非常火热的一条赛道。分子生物学当中有中心法则,所有的蛋白质是由一个 RNA 翻译而来的,RNA 又是从 DNA 转录而来,我们研究的是细胞当中的 DNA 每一个位点上、每一位的碱基对读出来是什么样的结果,是A、T、C还是 G ——这个过程叫做测序,就是把细胞的细胞核打开,然后把染色体拉直,通过仪器读取出它里面双螺旋中每一位上面的碱基对,因此这是一个非常微观世界中的巨大数据积累。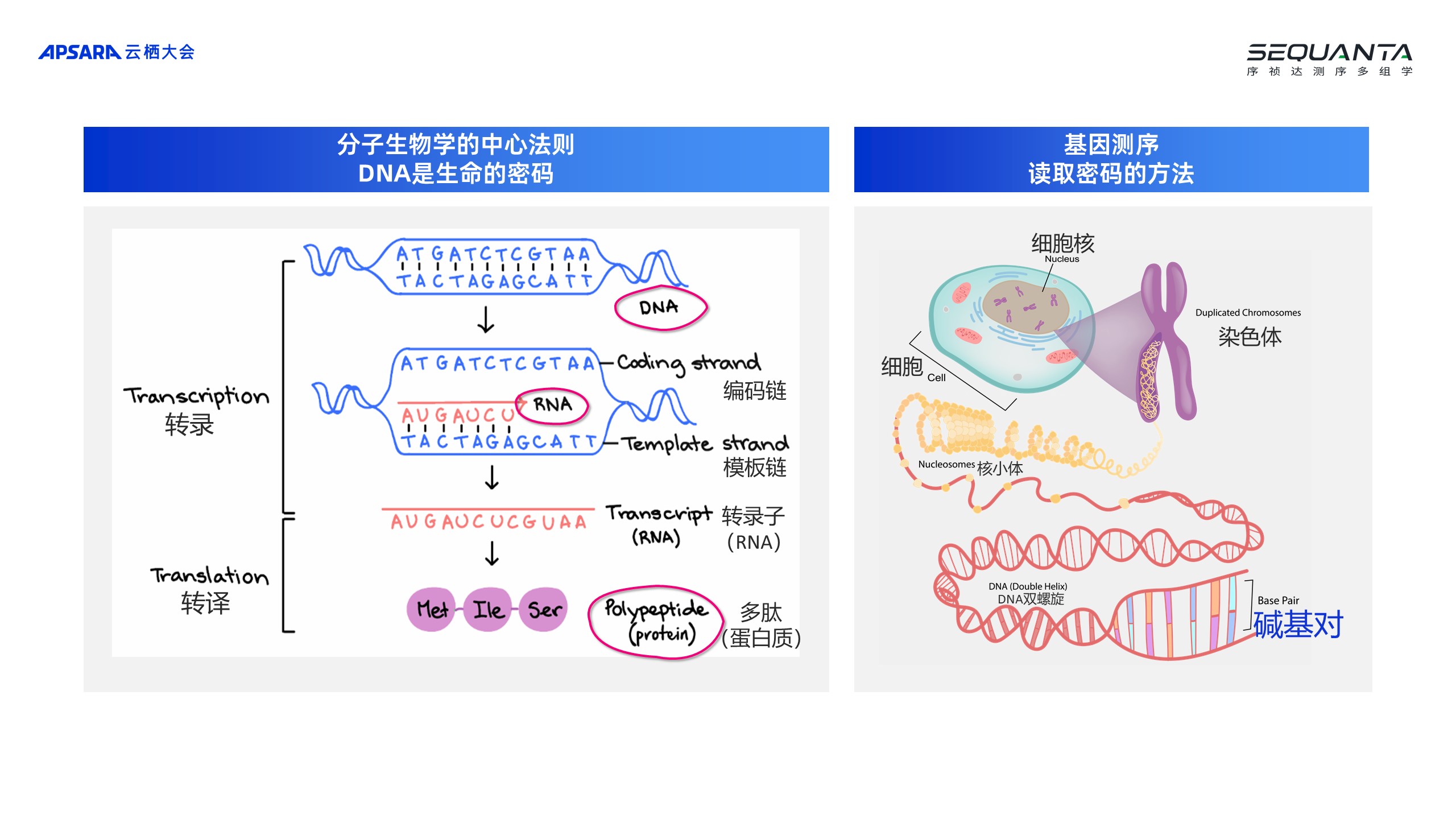 整个的测序过程也是非常复杂的。从生物样本处理最底下 DNA 的捕获、扩增,通过文库的制备,然后上机测序,一级分析去做碱基对读取,二级分析是基因组组装、变异分析。很早之前,阿里云有一个专门的产品叫做基因计算云,现在已经升级并到HPC里面,因此可以看到整个基因的计算,会占用大量的运算资源。
整个的测序过程也是非常复杂的。从生物样本处理最底下 DNA 的捕获、扩增,通过文库的制备,然后上机测序,一级分析去做碱基对读取,二级分析是基因组组装、变异分析。很早之前,阿里云有一个专门的产品叫做基因计算云,现在已经升级并到HPC里面,因此可以看到整个基因的计算,会占用大量的运算资源。 三、闪测实验室:阿里云高性能平台的加持,让测序触手可及我们希望能把整个测序组学领域的成本打下来,同时将速度提上去,因为原先的研究进度太慢,一个测序都要等很久。
三、闪测实验室:阿里云高性能平台的加持,让测序触手可及我们希望能把整个测序组学领域的成本打下来,同时将速度提上去,因为原先的研究进度太慢,一个测序都要等很久。 2020年,我们开始尝试闪测实验室的模式,把一个巨大的中心实验室化整为零,放到全国各地,在当地本地化服务当地客户,包括临床的研究公司、大学、药物研发企业,将实验室变成一个一个非常小的测序单元,小到一个闪测实验室只有四五个实验员,每天可以处理几百个样本,一天产生6 TB 以上的数据。通过这样的模式帮助到客户,让他们每天都能把样本送到实验室,每两天把结果交付给客户。
2020年,我们开始尝试闪测实验室的模式,把一个巨大的中心实验室化整为零,放到全国各地,在当地本地化服务当地客户,包括临床的研究公司、大学、药物研发企业,将实验室变成一个一个非常小的测序单元,小到一个闪测实验室只有四五个实验员,每天可以处理几百个样本,一天产生6 TB 以上的数据。通过这样的模式帮助到客户,让他们每天都能把样本送到实验室,每两天把结果交付给客户。
 真正的实现测序服务的降本和增效的关键有三点:1. IT基础设施云化;2. 流程标准化和自动化;3. 业务数字化和智能化。
真正的实现测序服务的降本和增效的关键有三点:1. IT基础设施云化;2. 流程标准化和自动化;3. 业务数字化和智能化。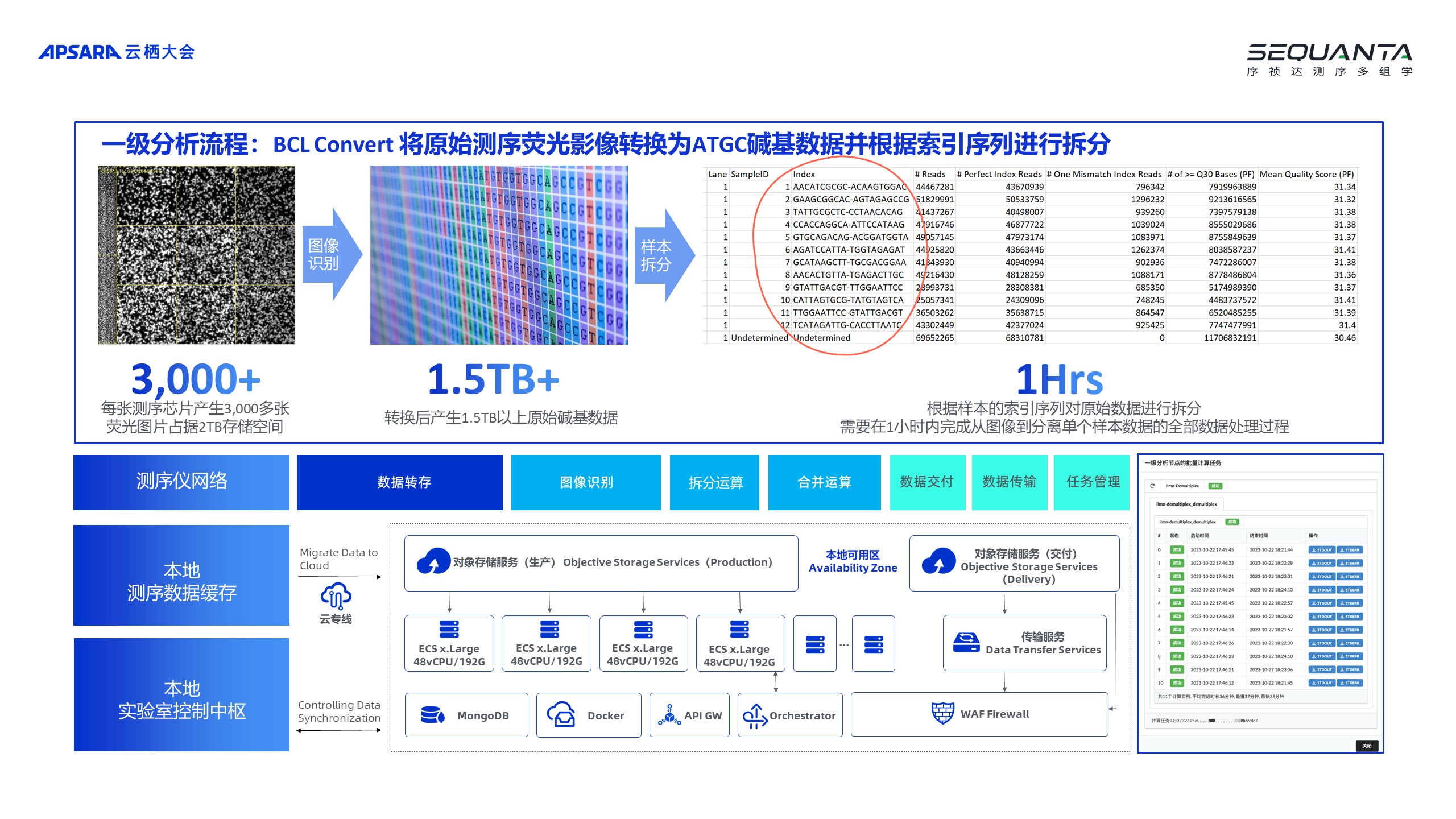 以一级分析的流程为例,把测序仪产生的照片,每张测序芯片每次要产生3000多张图片,一张图片600M~700M,然后把它识别出来,转换成 ATGC碱基数据,再根据 index 索引把中间的样本去分拆出来,因为通常一次一个芯片上面会放几百个不同的样本,所有的事情要在一个小时里面完成,一个小时要分析几个 TB 的数据,中间还带有图像识别,还要去写、去读数据,在以前很慢做不到,2023年初阿里云考虑不考虑升级一下,因为以前用的批量计算功能,只有我们一家在用,2017年的产品已经过时。云计算是会升级的。在2023年的年初,我们开始升级,从原来的批量计算迁移到了阿里云的 HPC 平台,用到了调度器、大型的HPC实例,然后发现升级之后的存储变得非常快,原来的存储性能是达不到使用要求的,升级之后 OSS 本身的性能以及计算实例的性能都得到非常大的提升。通过这次迁移,我们把本地测序数据缓存到云上 OSS,然后分配到 HPC 的环境当中,最后还是通过云交付给客户,真正实现了测序数据下机之后一个小时内完成分配。目前,已经在上海、北京、武汉、广州、深圳以及成都部署了闪测门店,一共6个城市八家门店,北京和上海的城市有多家门店,通过主流的测序平台I11umina Novaseq 6000和华大的体系为客户提供测序服务的交付。2. 阿里云多可用区的弹性高性能计算调度,加速计算
以一级分析的流程为例,把测序仪产生的照片,每张测序芯片每次要产生3000多张图片,一张图片600M~700M,然后把它识别出来,转换成 ATGC碱基数据,再根据 index 索引把中间的样本去分拆出来,因为通常一次一个芯片上面会放几百个不同的样本,所有的事情要在一个小时里面完成,一个小时要分析几个 TB 的数据,中间还带有图像识别,还要去写、去读数据,在以前很慢做不到,2023年初阿里云考虑不考虑升级一下,因为以前用的批量计算功能,只有我们一家在用,2017年的产品已经过时。云计算是会升级的。在2023年的年初,我们开始升级,从原来的批量计算迁移到了阿里云的 HPC 平台,用到了调度器、大型的HPC实例,然后发现升级之后的存储变得非常快,原来的存储性能是达不到使用要求的,升级之后 OSS 本身的性能以及计算实例的性能都得到非常大的提升。通过这次迁移,我们把本地测序数据缓存到云上 OSS,然后分配到 HPC 的环境当中,最后还是通过云交付给客户,真正实现了测序数据下机之后一个小时内完成分配。目前,已经在上海、北京、武汉、广州、深圳以及成都部署了闪测门店,一共6个城市八家门店,北京和上海的城市有多家门店,通过主流的测序平台I11umina Novaseq 6000和华大的体系为客户提供测序服务的交付。2. 阿里云多可用区的弹性高性能计算调度,加速计算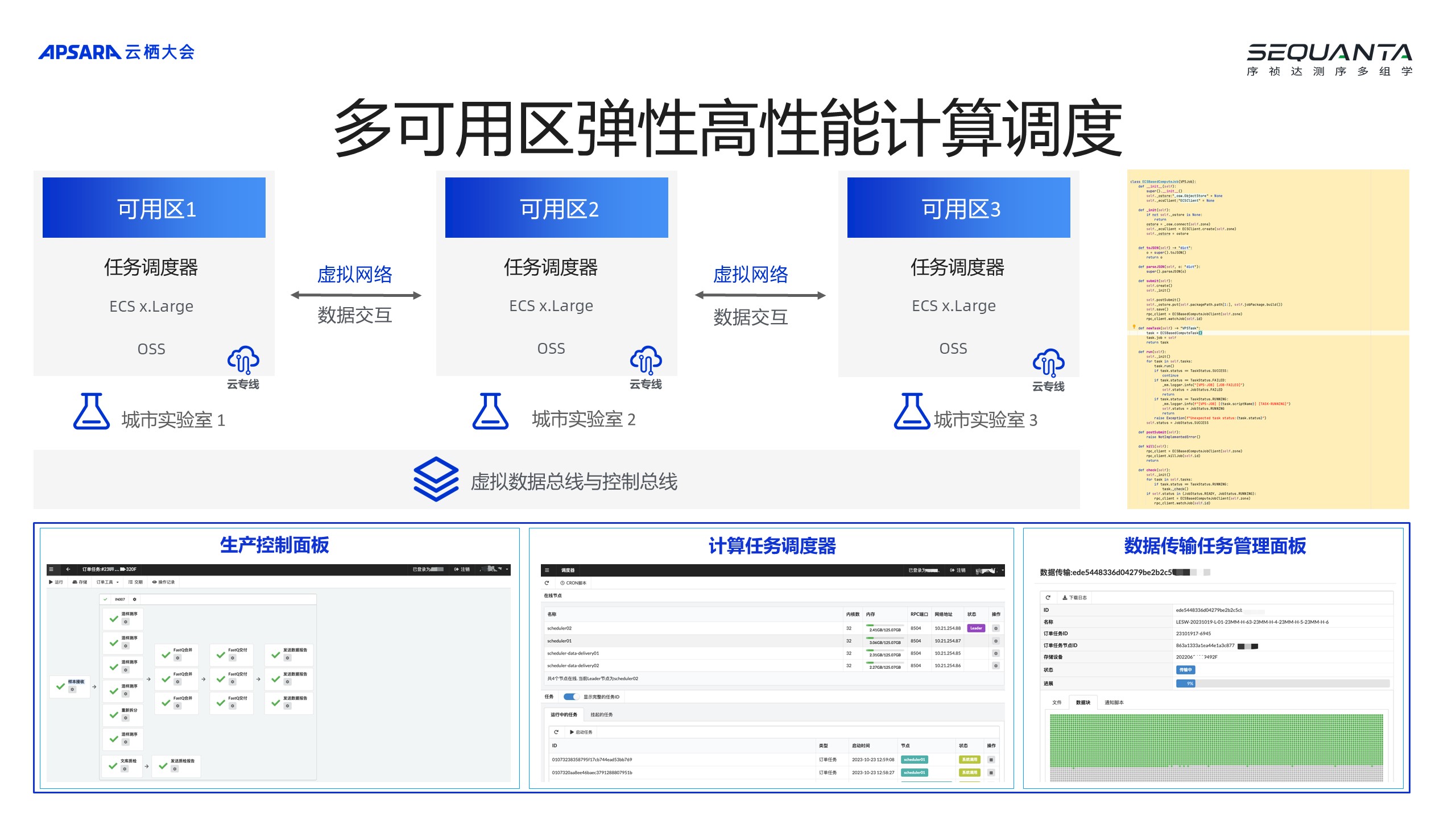 上图展示的是我们调度器的情况。整个交付是整个跨地域的,所以2023年我们做了一个非常大的调整,把它调整成支持多可用区的模式,不同城市的实验室通过专线到达当地的可用区,调度当地可用区上的资源来进行高性能的计算。与此同时,我们还自研了相关的一些数字化工具,包括生产控制平台、计算任务的调度器等,可以很好地将这些数据传输给客户,效果非常好。
上图展示的是我们调度器的情况。整个交付是整个跨地域的,所以2023年我们做了一个非常大的调整,把它调整成支持多可用区的模式,不同城市的实验室通过专线到达当地的可用区,调度当地可用区上的资源来进行高性能的计算。与此同时,我们还自研了相关的一些数字化工具,包括生产控制平台、计算任务的调度器等,可以很好地将这些数据传输给客户,效果非常好。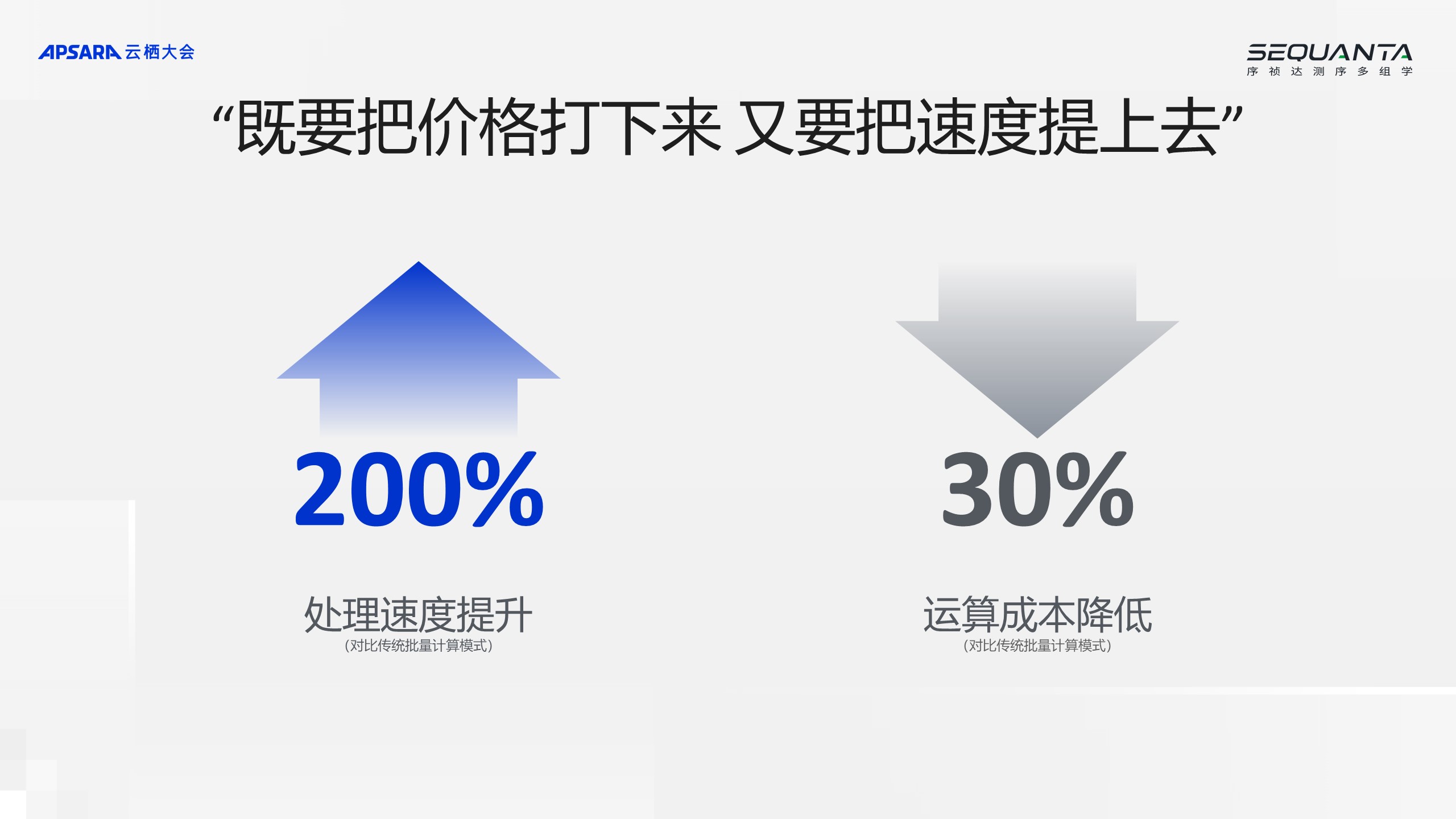 对比原来的批量计算模式,处理速度提升了200%,运算成本降低了30%。所以,和阿里云合作的几年里,让承诺兑现了,让高通量测序服务变得触手可及,每一个大学甚至大学生在研究小老鼠、斑马鱼时,都可以非常方便地使用测序服务,最低送1个 G 的样本都可以测,最快48个小时就能交付,不仅快还很便宜,一个季度只要30多元就可以进行测序,这当中已经覆盖了所有的费用,包括测序实验室的费用、云平台的费用等。
对比原来的批量计算模式,处理速度提升了200%,运算成本降低了30%。所以,和阿里云合作的几年里,让承诺兑现了,让高通量测序服务变得触手可及,每一个大学甚至大学生在研究小老鼠、斑马鱼时,都可以非常方便地使用测序服务,最低送1个 G 的样本都可以测,最快48个小时就能交付,不仅快还很便宜,一个季度只要30多元就可以进行测序,这当中已经覆盖了所有的费用,包括测序实验室的费用、云平台的费用等。
