安谋科技(Arm China)马闯:Arm架构下性能分析与优化介绍[阿里云]
 为了更好地方便各位开发者和用户了解并应用ECS倚天实例,由阿里云弹性计算联合基础软件团队 & 平头哥 & 安谋科技(Arm China)共同发起的【倚天实例迁移课程】正式上线,本次系列课程共计10节,共分为基础篇、架构迁移篇、性能优化篇等三个篇章,从不同角度为用户带来更加丰富和专业的讲解。2023年9月19日,系列课程第九节《Arm®架构下性能分析与优化介绍》正式上线,由安谋科技 (Arm China)主任工程师马闯主讲,内容涵盖:Arm架构下性能监控单元 (PMU) 介绍、Arm统计性能分析扩展 (SPE) 介绍、Arm性能分析工具介绍、Arm架构下性能优化案例分享,本期节目在阿里云官网、阿里云微信视频号、阿里云钉钉视频号、InfoQ官网、阿里云开发者微信视频号、阿里云创新中心直播平台 & 微信视频号同步播出,同时可以点击【https://developer.aliyun.com/topic/ecs-yitian】进入【倚天实例迁移课程官网】了解更多内容。以下内容根据马闯的演讲整理而成,供阅览:
为了更好地方便各位开发者和用户了解并应用ECS倚天实例,由阿里云弹性计算联合基础软件团队 & 平头哥 & 安谋科技(Arm China)共同发起的【倚天实例迁移课程】正式上线,本次系列课程共计10节,共分为基础篇、架构迁移篇、性能优化篇等三个篇章,从不同角度为用户带来更加丰富和专业的讲解。2023年9月19日,系列课程第九节《Arm®架构下性能分析与优化介绍》正式上线,由安谋科技 (Arm China)主任工程师马闯主讲,内容涵盖:Arm架构下性能监控单元 (PMU) 介绍、Arm统计性能分析扩展 (SPE) 介绍、Arm性能分析工具介绍、Arm架构下性能优化案例分享,本期节目在阿里云官网、阿里云微信视频号、阿里云钉钉视频号、InfoQ官网、阿里云开发者微信视频号、阿里云创新中心直播平台 & 微信视频号同步播出,同时可以点击【https://developer.aliyun.com/topic/ecs-yitian】进入【倚天实例迁移课程官网】了解更多内容。以下内容根据马闯的演讲整理而成,供阅览: 一、基于性能监控单元 (PMU) 的分析
一、基于性能监控单元 (PMU) 的分析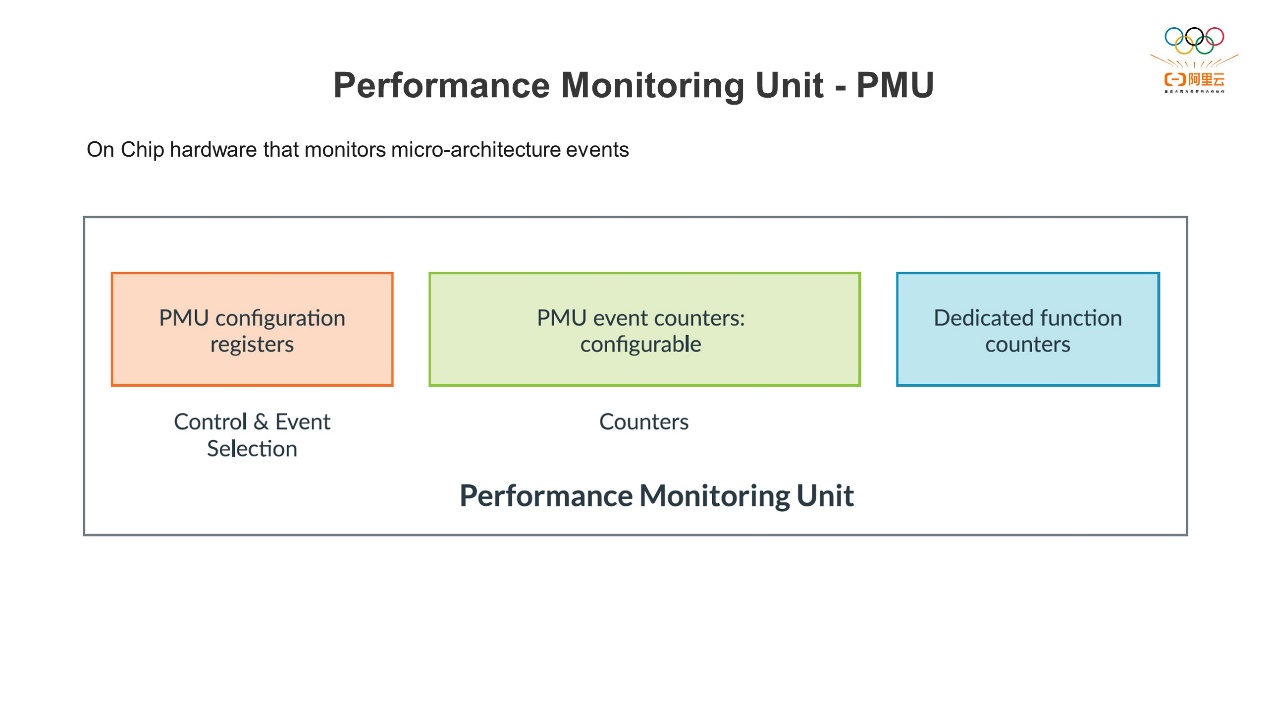 首先我们介绍基于CPU微架构的硬件事件 (Event) 进行分析的方法。通常软件在服务器上运行的时候,我们想了解软件的运行状态有多种方式,比如可以通过软件的日志了解它的运行状态、错误信息等等。同时,我们还可以监控这台服务器上各种资源的使用情况,包括CPU的使用率、内存、网络、磁盘IO等等数据。这些数据相结合就可以评估服务器整体程序时的监控状况。那么这些资源是否得到了充分利用呢?我们通常可以通过调整软件或者系统的参数进行优化,但如果我们想要更深入地了解CPU在软件运行中的状态是否存在瓶颈,就需要知道底层硬件的信息。在这种情况下,我们就需要用硬件的监控技术来实现了,也就是我们通常说的Hardware to Monitor Hardware。现代处理器通常都配备了性能监控单元 (Performance Monitoring Unit, PMU) 来监控硬件的运行状态。PMU可以跟踪底层的硬件事件,比如跟CPU相关的事件、执行的指令个数、时钟周期数等等;还有一些与缓存相关的事件,比如指令缓存 (ICache) 缺失、ICache的访问次数等等;还有跟TLB相关的事件。这些事件结合在一起就可以反映出程序执行期间CPU的行为,帮助我们更好地对程序进行分析和调优。Arm平台的PMU主要包括三个部分:
首先我们介绍基于CPU微架构的硬件事件 (Event) 进行分析的方法。通常软件在服务器上运行的时候,我们想了解软件的运行状态有多种方式,比如可以通过软件的日志了解它的运行状态、错误信息等等。同时,我们还可以监控这台服务器上各种资源的使用情况,包括CPU的使用率、内存、网络、磁盘IO等等数据。这些数据相结合就可以评估服务器整体程序时的监控状况。那么这些资源是否得到了充分利用呢?我们通常可以通过调整软件或者系统的参数进行优化,但如果我们想要更深入地了解CPU在软件运行中的状态是否存在瓶颈,就需要知道底层硬件的信息。在这种情况下,我们就需要用硬件的监控技术来实现了,也就是我们通常说的Hardware to Monitor Hardware。现代处理器通常都配备了性能监控单元 (Performance Monitoring Unit, PMU) 来监控硬件的运行状态。PMU可以跟踪底层的硬件事件,比如跟CPU相关的事件、执行的指令个数、时钟周期数等等;还有一些与缓存相关的事件,比如指令缓存 (ICache) 缺失、ICache的访问次数等等;还有跟TLB相关的事件。这些事件结合在一起就可以反映出程序执行期间CPU的行为,帮助我们更好地对程序进行分析和调优。Arm平台的PMU主要包括三个部分:
- 配置寄存器,它允许用户或者软件自己配置,监控我们想要获得的硬件事件。
- 记录事件的计数器 (Counter),记录特定事件的发生次数。通常每个核心都有多个PMU的计数器,方便我们在同一时间监控多个事件。
- 专用的计数器,用来记录CPU周期 (Cycle)。
 下面介绍一下Arm平台上事件的三种分类,这里会涉及到Arm架构和微架构的概念。架构可以理解为一个指令集,包括内存模型 (Memory model)、行动规范等等,可以理解为是一个标准,它会定义CPU怎么工作或者一种对工作行为的预期,并不会限制或者去定义怎么设计以及实现。微架构是实际的CPU的设计,包括流水线、前端、后端的具体设计,这个由各个芯片厂商自行开发。接下来介绍一下事件,它大致可以分为三种:第一种,和架构相关,必须要实现的强制事件 (Mandatory events)。只要使用Arm架构,在设计CPU的时候这部分的事件就一定要实现。第二种,常见可选事件 (Common optional events)。在设计CPU的时候,厂商可以根据自己的需求选择这类事件进行实现。这里还专门提到了SBSA的认证,它是针对服务器的一个规范。如果芯片厂商设计的CPU要用于服务器领域,虽然有些事件属于常见可选,但如果需要通过SBSA的认证,也必须去实现,这样可以让服务器市场有一个比较规范的统一标准。第三种,完全依赖于微架构实现的,各个芯片厂商可以根据自己需求定义自己的事件,方便后期做事件的统计和分析。
下面介绍一下Arm平台上事件的三种分类,这里会涉及到Arm架构和微架构的概念。架构可以理解为一个指令集,包括内存模型 (Memory model)、行动规范等等,可以理解为是一个标准,它会定义CPU怎么工作或者一种对工作行为的预期,并不会限制或者去定义怎么设计以及实现。微架构是实际的CPU的设计,包括流水线、前端、后端的具体设计,这个由各个芯片厂商自行开发。接下来介绍一下事件,它大致可以分为三种:第一种,和架构相关,必须要实现的强制事件 (Mandatory events)。只要使用Arm架构,在设计CPU的时候这部分的事件就一定要实现。第二种,常见可选事件 (Common optional events)。在设计CPU的时候,厂商可以根据自己的需求选择这类事件进行实现。这里还专门提到了SBSA的认证,它是针对服务器的一个规范。如果芯片厂商设计的CPU要用于服务器领域,虽然有些事件属于常见可选,但如果需要通过SBSA的认证,也必须去实现,这样可以让服务器市场有一个比较规范的统一标准。第三种,完全依赖于微架构实现的,各个芯片厂商可以根据自己需求定义自己的事件,方便后期做事件的统计和分析。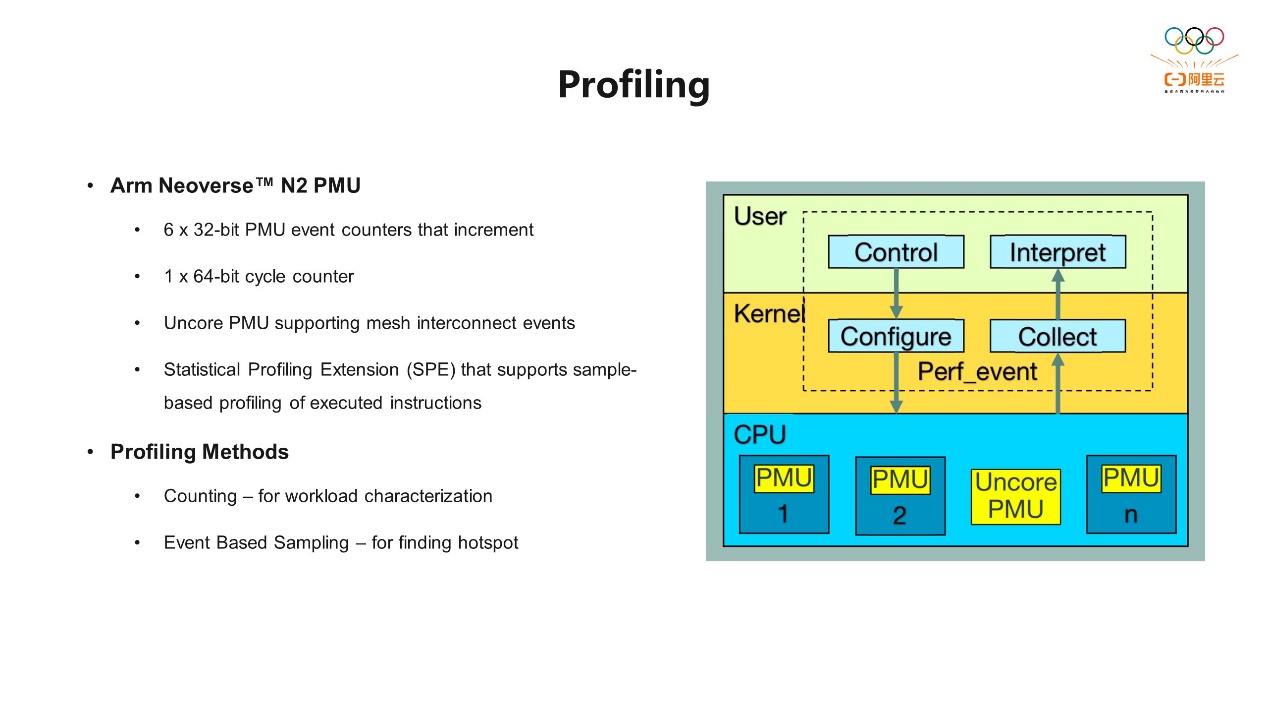 这是Arm Neoverse™ N2平台上PMU的简要介绍。在2021年10月,平头哥就推出了全球首个五纳米制程的倚天710芯片。这个芯片就是基于ArmNeoverse N2平台而开发核心,主要面向云数据中心服务器中高性能的CPU芯片。从上图可以看到,在每个CPU核心上都有六个PMU计数器,也就是说我们在同一时间可以同时采集六种不同类型的硬件事件。另外,我们还有一个专门收集CPU周期的计数器,还包括一些Uncore的PMU计数器。Uncore的意思是,比如倚天710有128个核心,核心和核心之间互相相连,和外设也会相连,它们互联互通的时候会产生一些事件,Uncore的PMU的计数器就会记录这些事件。还有一个是统计分析扩展 (Statistical Profiling Extension, SPE),它是通过硬件的方式实现对指令进行采样。通常我们有两种分析问题的方式:第一种,计数 (Counting),即记录某一时间段内发生的硬件事件的次数。这种方法的准确度会比较高,额外的开销也比较少。因为我们有专门的PMU硬件的组件在CPU核心里,它可以直接收集相关的事件。刚才我们提到最多是六个,如果超过六个,常用的软件可以通过复用的方式收集。第二种,采样,也是我们常用的性能分析的方法,方便我们找到程序中的热点区域。这种方法是在PMU计数器在预设的事件数量,溢出之后会产生一个中断,这个中断会记录当前CPU的信息状态,包括指令的指针、寄存器的状态等信息,相当于在那一时刻为系统拍摄了一个快照。最终这些信息会上传给上层的软件,用于后续的分析。这些采样数据会包含栈的跟踪、函数注释,有助于我们找到产生事件库的代码。但采样的准确性相对差一些,因为它依赖于产生的中断来收集信息,而中断的产生和执行本身也需要一些执行指令,所以会花费一些时间,也会引入一定的性能开销。尽管准确度有一定的限制,但如果是大量的事件和采样,它依然可以近似地确定代码中的热点函数。
这是Arm Neoverse™ N2平台上PMU的简要介绍。在2021年10月,平头哥就推出了全球首个五纳米制程的倚天710芯片。这个芯片就是基于ArmNeoverse N2平台而开发核心,主要面向云数据中心服务器中高性能的CPU芯片。从上图可以看到,在每个CPU核心上都有六个PMU计数器,也就是说我们在同一时间可以同时采集六种不同类型的硬件事件。另外,我们还有一个专门收集CPU周期的计数器,还包括一些Uncore的PMU计数器。Uncore的意思是,比如倚天710有128个核心,核心和核心之间互相相连,和外设也会相连,它们互联互通的时候会产生一些事件,Uncore的PMU的计数器就会记录这些事件。还有一个是统计分析扩展 (Statistical Profiling Extension, SPE),它是通过硬件的方式实现对指令进行采样。通常我们有两种分析问题的方式:第一种,计数 (Counting),即记录某一时间段内发生的硬件事件的次数。这种方法的准确度会比较高,额外的开销也比较少。因为我们有专门的PMU硬件的组件在CPU核心里,它可以直接收集相关的事件。刚才我们提到最多是六个,如果超过六个,常用的软件可以通过复用的方式收集。第二种,采样,也是我们常用的性能分析的方法,方便我们找到程序中的热点区域。这种方法是在PMU计数器在预设的事件数量,溢出之后会产生一个中断,这个中断会记录当前CPU的信息状态,包括指令的指针、寄存器的状态等信息,相当于在那一时刻为系统拍摄了一个快照。最终这些信息会上传给上层的软件,用于后续的分析。这些采样数据会包含栈的跟踪、函数注释,有助于我们找到产生事件库的代码。但采样的准确性相对差一些,因为它依赖于产生的中断来收集信息,而中断的产生和执行本身也需要一些执行指令,所以会花费一些时间,也会引入一定的性能开销。尽管准确度有一定的限制,但如果是大量的事件和采样,它依然可以近似地确定代码中的热点函数。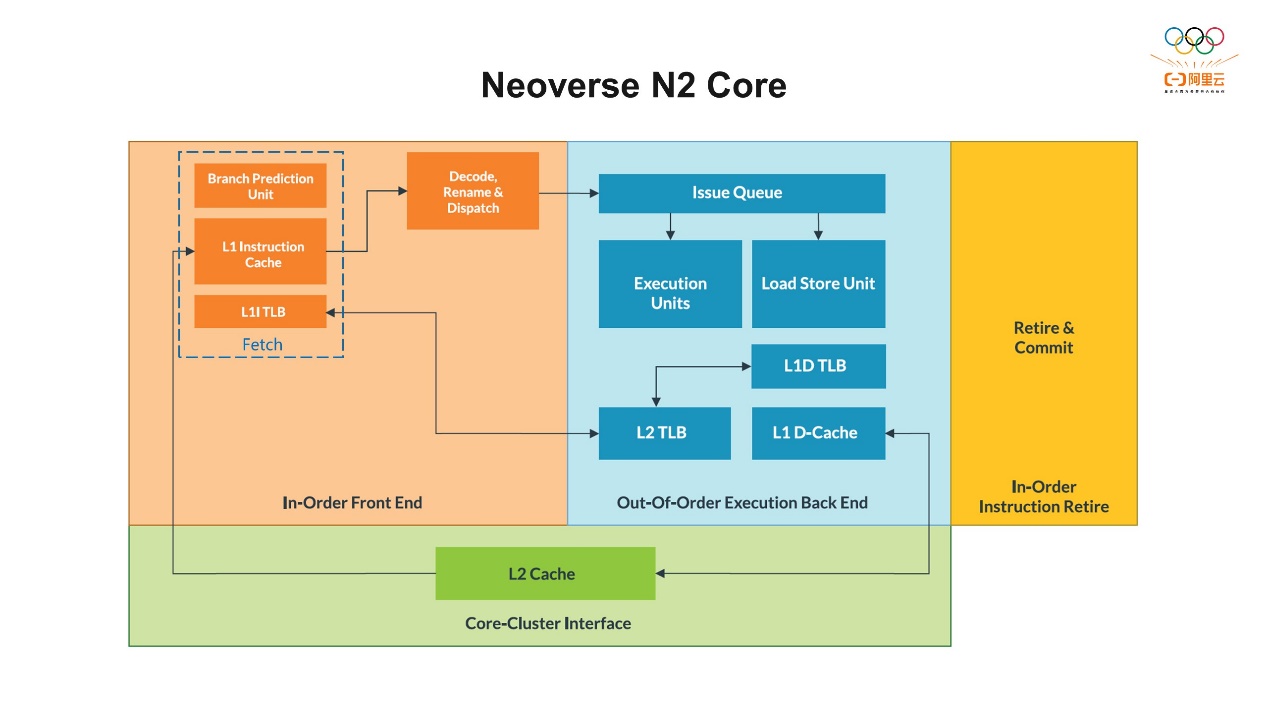 接下来我们先了解一下Neoverse N2核心的微架构的结构图。通常指令一般分为取指、译码、执行、写回四个阶段,通常我们把指令的处理分为前端和后端。前端负责把指令从内存中预取到CPU,并将它解码、分发和重命名等操作,最终发射到后端。在前端指令的执行都是顺序的 (In-order)。在N2核心上,一个CPU周期最多可以同时解码四条指令到后端,然后后端执行这些指令。后端负责指令的执行,包括几个执行单元,比如整数、浮点数、Load Store以及并行计算。Arm架构的后端可以乱序执行 (Out-Of-Order)。如果这些指令之间没有依赖的话,就可以乱序执行,这样可以最大程度地提高指令执行的效率。此外,在微服务架构里还有两个非常重要的部分,一个是缓存 (Cache),另外一个是转译后备缓冲区 (Translation Lookaside Buffer, TLB)。缓存分为两种,一种是指令缓存 (ICache),位于前端,用来存储指令;还有一种是数据缓存 (DCache),位于后端,用来存储数据。访问缓存的延迟/命中率,对整体CPU运行的效率有非常大的影响。TLB是虚拟地址向物理地址转换的映射表,它用来加速内存地址的转换,帮助CPU快速找到虚拟内存到物理内存的地址的映射,从而减少内存的访问。TLB也分为ITLB和DTLB,针对指令的TLB在前端,针对数据的TLB在后端。一条指令在前端准备好,后端执行完之后最终会成功退役,这是我们最希望看到的结果。
接下来我们先了解一下Neoverse N2核心的微架构的结构图。通常指令一般分为取指、译码、执行、写回四个阶段,通常我们把指令的处理分为前端和后端。前端负责把指令从内存中预取到CPU,并将它解码、分发和重命名等操作,最终发射到后端。在前端指令的执行都是顺序的 (In-order)。在N2核心上,一个CPU周期最多可以同时解码四条指令到后端,然后后端执行这些指令。后端负责指令的执行,包括几个执行单元,比如整数、浮点数、Load Store以及并行计算。Arm架构的后端可以乱序执行 (Out-Of-Order)。如果这些指令之间没有依赖的话,就可以乱序执行,这样可以最大程度地提高指令执行的效率。此外,在微服务架构里还有两个非常重要的部分,一个是缓存 (Cache),另外一个是转译后备缓冲区 (Translation Lookaside Buffer, TLB)。缓存分为两种,一种是指令缓存 (ICache),位于前端,用来存储指令;还有一种是数据缓存 (DCache),位于后端,用来存储数据。访问缓存的延迟/命中率,对整体CPU运行的效率有非常大的影响。TLB是虚拟地址向物理地址转换的映射表,它用来加速内存地址的转换,帮助CPU快速找到虚拟内存到物理内存的地址的映射,从而减少内存的访问。TLB也分为ITLB和DTLB,针对指令的TLB在前端,针对数据的TLB在后端。一条指令在前端准备好,后端执行完之后最终会成功退役,这是我们最希望看到的结果。 上图中罗列了一些Neoverse N2上主要的硬件事件,大概有150多种事件。不过这些只是一些数字,也就是原始数据,直接看的话很难理解性能是好是坏。所以为了更好地理解这些事件并评估CPU的性能,通常会定义一些指标,通过这些指标判断原始事件是否可以提供有意义的性能分析。从上图可以看到,我们针对不同的类别,包括缓存的使用效率、TLB的使用效率等定义了一系列指标,这些指标就是一个个的公式,你可以根据指标判断CPU的行为以及性能的特征。有了这些指标之后,我们就可以自己写分析工具了。举个简单的例子,是用Json文件看一下Branch MKPI这个指标,这个指标是(BR_MIS_PRED_RETIRED/INST_RETIRED)*1000,即每1000条指令中有多少条出现了BR_MIS。通过收集事件,再通过工具把它计算出来。有了这些指标之后,就可以看到一些相对直观的数据,比如缓存缺失率是多少,命中率是多少。那么有了这些指标之后,实际上我们还是需要有一个更合适且合理的方法,来利用它们找到系统的瓶颈。
上图中罗列了一些Neoverse N2上主要的硬件事件,大概有150多种事件。不过这些只是一些数字,也就是原始数据,直接看的话很难理解性能是好是坏。所以为了更好地理解这些事件并评估CPU的性能,通常会定义一些指标,通过这些指标判断原始事件是否可以提供有意义的性能分析。从上图可以看到,我们针对不同的类别,包括缓存的使用效率、TLB的使用效率等定义了一系列指标,这些指标就是一个个的公式,你可以根据指标判断CPU的行为以及性能的特征。有了这些指标之后,我们就可以自己写分析工具了。举个简单的例子,是用Json文件看一下Branch MKPI这个指标,这个指标是(BR_MIS_PRED_RETIRED/INST_RETIRED)*1000,即每1000条指令中有多少条出现了BR_MIS。通过收集事件,再通过工具把它计算出来。有了这些指标之后,就可以看到一些相对直观的数据,比如缓存缺失率是多少,命中率是多少。那么有了这些指标之后,实际上我们还是需要有一个更合适且合理的方法,来利用它们找到系统的瓶颈。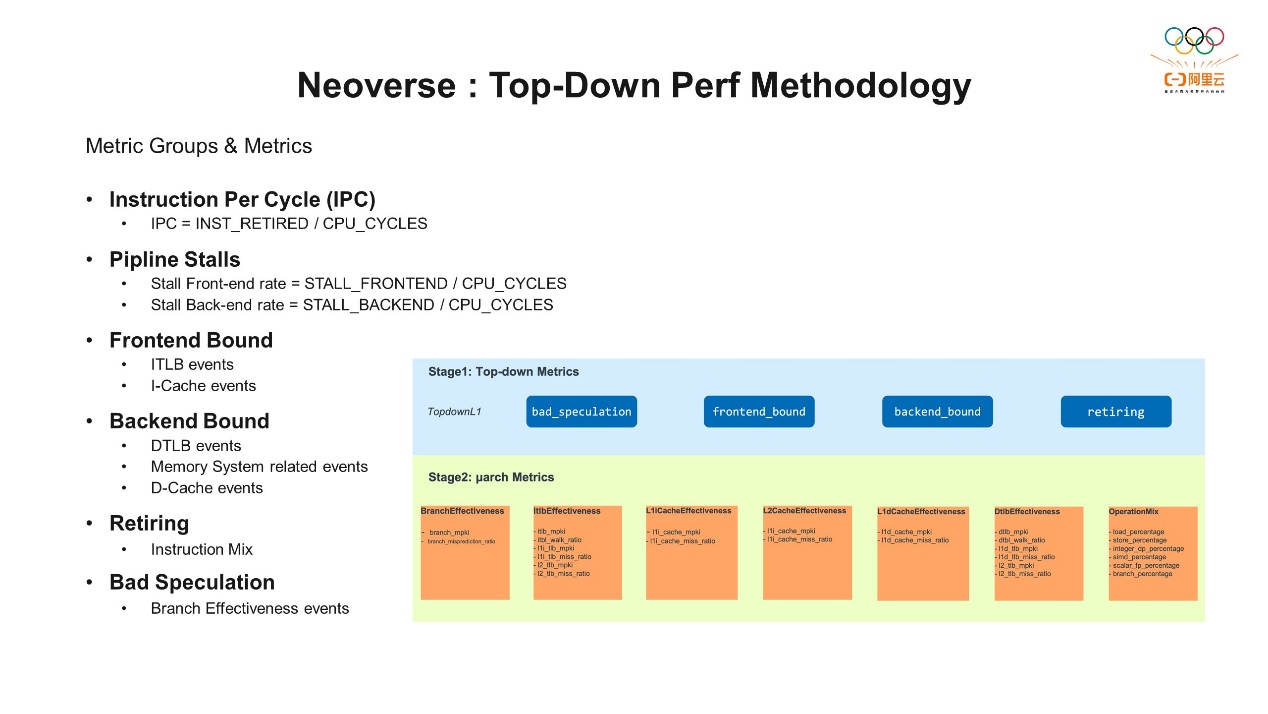 这里我们就要提到一种常用的分析方式叫Top-Down,它是一种基于CPU微架构的性能分析方法。核心思想是通过自顶向下的方式去关注性能优化的目标,并找到性能瓶颈。这个方法最早由Intel的一位工程师提出,并演化成了一套方法论,适用于各种CPU环境上的分析。它将CPU的资源和指令操作联系在一起,提供了一个通用的评估框架。通过对CPU微指令的分析,可以将应用程序的特征分为不同的倾向性。Top-Down分为两个阶段,阶段一也叫Top-Down的Level 1,Level 1和Intel的Top-Down解决方案是一致的,它分为四个部分,也就是一个应用程序在运行时它会有四种不同的倾向性,分别是前端bound、后端bound、错误的分支预测、指令的退役。
这里我们就要提到一种常用的分析方式叫Top-Down,它是一种基于CPU微架构的性能分析方法。核心思想是通过自顶向下的方式去关注性能优化的目标,并找到性能瓶颈。这个方法最早由Intel的一位工程师提出,并演化成了一套方法论,适用于各种CPU环境上的分析。它将CPU的资源和指令操作联系在一起,提供了一个通用的评估框架。通过对CPU微指令的分析,可以将应用程序的特征分为不同的倾向性。Top-Down分为两个阶段,阶段一也叫Top-Down的Level 1,Level 1和Intel的Top-Down解决方案是一致的,它分为四个部分,也就是一个应用程序在运行时它会有四种不同的倾向性,分别是前端bound、后端bound、错误的分支预测、指令的退役。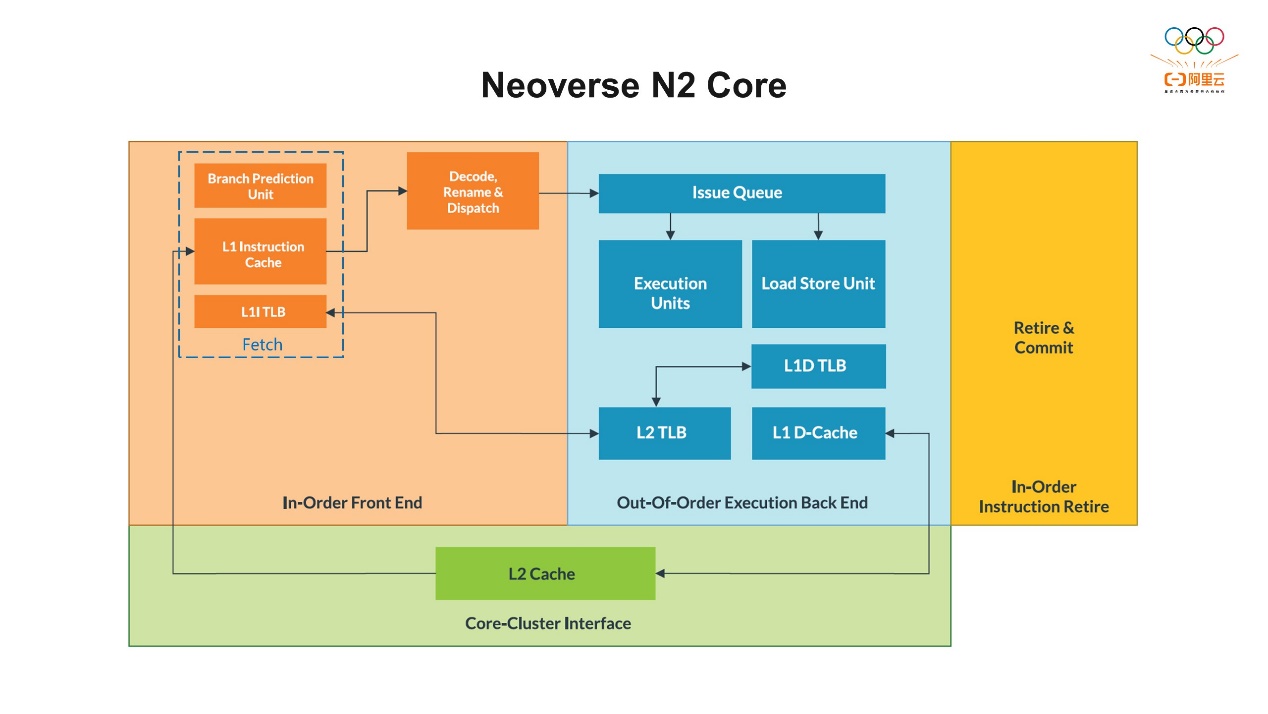 我们看一下上面这张图,为了找到CPU的瓶颈,重点是要分析出CPU流水线上它有多少时间没有真正地在处理指令,也就是CPU流水线上的利用率。然后分析一下没有处理指令时,是因为哪些方面没有协调好,导致它出现了流水线空转。我们通常把这种空转叫stall,所以我们经常说前端stall或者后端stall。比如分支预测失败之后,导致了一些指令没有正常的退役。针对空转,需要分析是前端的原因还是后端的原因,前端stall可能和相关的资源有关,比如ICache、ITLB等等;后端stall一般和DCache、DTLB有关,但也包括其他原因。所以通过微架构的结构图,再结合Top-Down的方式,就可以一步一步地定位到系统的瓶颈,这些最终还依赖于PMU提供的基础数据。
我们看一下上面这张图,为了找到CPU的瓶颈,重点是要分析出CPU流水线上它有多少时间没有真正地在处理指令,也就是CPU流水线上的利用率。然后分析一下没有处理指令时,是因为哪些方面没有协调好,导致它出现了流水线空转。我们通常把这种空转叫stall,所以我们经常说前端stall或者后端stall。比如分支预测失败之后,导致了一些指令没有正常的退役。针对空转,需要分析是前端的原因还是后端的原因,前端stall可能和相关的资源有关,比如ICache、ITLB等等;后端stall一般和DCache、DTLB有关,但也包括其他原因。所以通过微架构的结构图,再结合Top-Down的方式,就可以一步一步地定位到系统的瓶颈,这些最终还依赖于PMU提供的基础数据。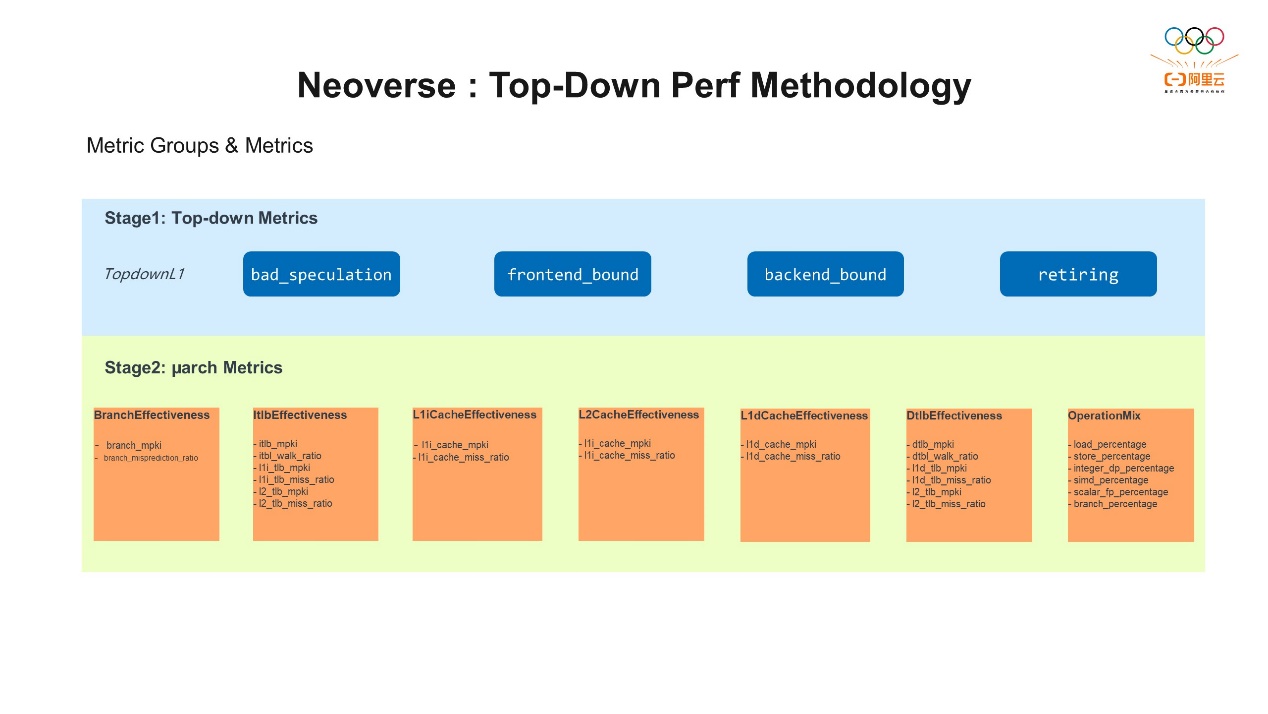 刚才提到出现stall后分析stall的原因有前端和后端。还有一部分叫错误的分支预测,它代表了一种特定的性能的瓶颈类型,与其他的类型有明显的区别。分支预测一般出现在CPU中非常关键的组成部分,它用于指导程序的一种执行的流程。但当分支预测失败的时候,CPU就必须回退到之前的状态,并重新开始执行不同分支上路径的指令。这种回退和重新开始通常会引入额外的时钟周期和指令执行,会导致性能的下降。因此,过高的错误分支预测会导致性能的损失。所以我们专门有一个性能错误的分支预测的指标来判断分支预测,有助于我们识别程序中分支预测的问题,并指导我们进行性能优化的工作。例如我们可以去代码里看看相关的热点,是否是分支错误产生的热点,是否有更好的算法和代码结构,减少分支预测失败的发生。此外,还有一个我们最希望看到的退役的指令的占比,理想情况下我们希望所有的指令都可以在运行过程中正常退役,因为它与我们后面要提到的每周期指令数 (Instruction Per Cycle, IPC) 是密切相关的。但退役比例过高是不是就没有优化空间呢?这个也是可以探讨的,它依赖于程序的运行状态或程序的运行场景。通过后面例子可以看到即使退役的指令占比较高,也还是有一定的优化空间。
刚才提到出现stall后分析stall的原因有前端和后端。还有一部分叫错误的分支预测,它代表了一种特定的性能的瓶颈类型,与其他的类型有明显的区别。分支预测一般出现在CPU中非常关键的组成部分,它用于指导程序的一种执行的流程。但当分支预测失败的时候,CPU就必须回退到之前的状态,并重新开始执行不同分支上路径的指令。这种回退和重新开始通常会引入额外的时钟周期和指令执行,会导致性能的下降。因此,过高的错误分支预测会导致性能的损失。所以我们专门有一个性能错误的分支预测的指标来判断分支预测,有助于我们识别程序中分支预测的问题,并指导我们进行性能优化的工作。例如我们可以去代码里看看相关的热点,是否是分支错误产生的热点,是否有更好的算法和代码结构,减少分支预测失败的发生。此外,还有一个我们最希望看到的退役的指令的占比,理想情况下我们希望所有的指令都可以在运行过程中正常退役,因为它与我们后面要提到的每周期指令数 (Instruction Per Cycle, IPC) 是密切相关的。但退役比例过高是不是就没有优化空间呢?这个也是可以探讨的,它依赖于程序的运行状态或程序的运行场景。通过后面例子可以看到即使退役的指令占比较高,也还是有一定的优化空间。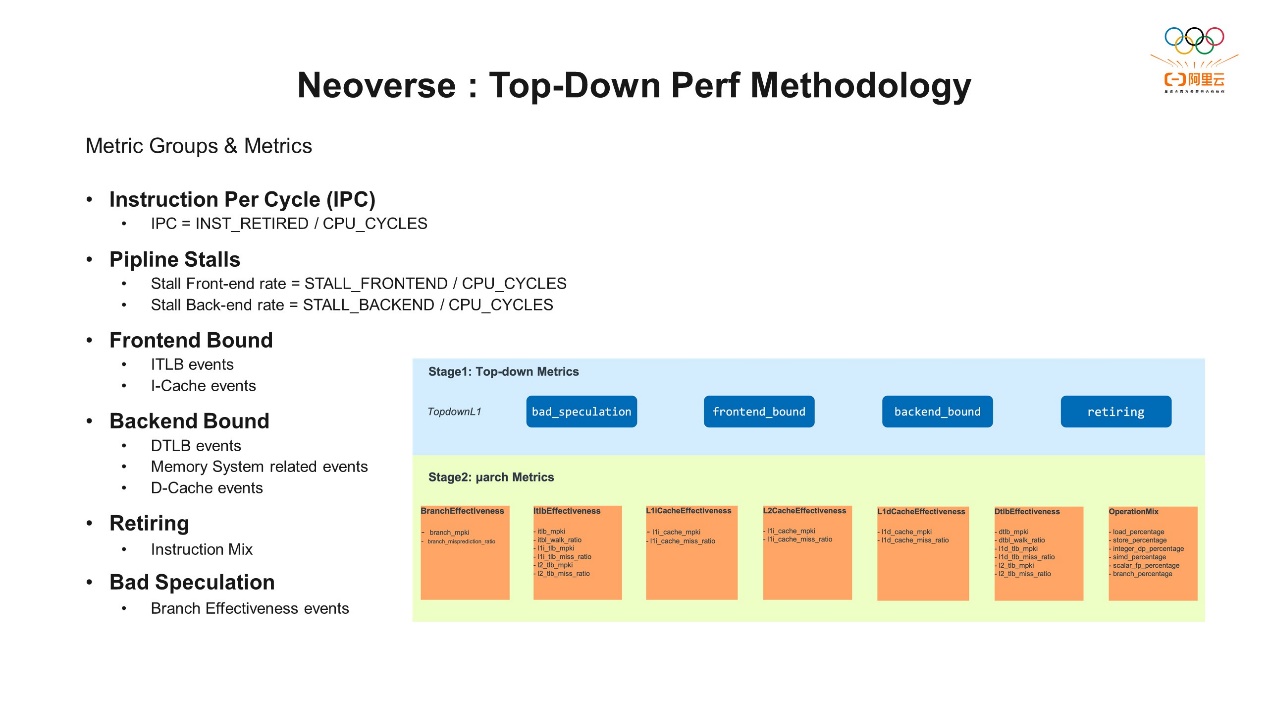 上图中阶段二是微架构层面的指标,也是Arm Top-Down完整的解决方案的一部分。另外,IPC也是一个比较重要的指标,每个CPU最多可以有多少条指令正常的退役。因为我刚才提到N2上前端同时最多可以解码四条指令,所以理想的状态下是IPC=4是它的最高值。这里我们可以想一下,如果IPC真的达到4了,是不是就表示程序的性能非常好呢?答案是不一定的,要看在IPC=4的时候,程序到底在做什么工作。比如它在做一个死循环或者自旋锁 (Spin lock),虽然看起来CPU非常忙,而且运行也非常顺利,所有的指令都退役了,但它陷入了一种循环的状态,并没有执行软件本身想要做的工作,这也是对CPU的一种浪费。所以这里再次强调,这些指标都要结合实际情况分析,单独某个指标,比如IPC过高也不一定表示它的性能更好。下一个是Pipeline Stalls,可以看到前端Stall rate和后端Stall rate,后面是对应阶段二的一些指标。前端bound、后端bound、错误的分支预测、指令的退役这四个就是我们刚才说的Top-Down的四个指标。我们发现了这个软件的前端Bound、后端Bound、错误的分支预测、指令的退役它的占比哪一个倾向性更高,都可以到阶段二的微架构里查看相关的指标,是什么原因导致占比过高。比如前端我们可以看ITLB 事件和ICache相关的指标,后端是数据相关的,可以看一些和系统内存相关的事件。
上图中阶段二是微架构层面的指标,也是Arm Top-Down完整的解决方案的一部分。另外,IPC也是一个比较重要的指标,每个CPU最多可以有多少条指令正常的退役。因为我刚才提到N2上前端同时最多可以解码四条指令,所以理想的状态下是IPC=4是它的最高值。这里我们可以想一下,如果IPC真的达到4了,是不是就表示程序的性能非常好呢?答案是不一定的,要看在IPC=4的时候,程序到底在做什么工作。比如它在做一个死循环或者自旋锁 (Spin lock),虽然看起来CPU非常忙,而且运行也非常顺利,所有的指令都退役了,但它陷入了一种循环的状态,并没有执行软件本身想要做的工作,这也是对CPU的一种浪费。所以这里再次强调,这些指标都要结合实际情况分析,单独某个指标,比如IPC过高也不一定表示它的性能更好。下一个是Pipeline Stalls,可以看到前端Stall rate和后端Stall rate,后面是对应阶段二的一些指标。前端bound、后端bound、错误的分支预测、指令的退役这四个就是我们刚才说的Top-Down的四个指标。我们发现了这个软件的前端Bound、后端Bound、错误的分支预测、指令的退役它的占比哪一个倾向性更高,都可以到阶段二的微架构里查看相关的指标,是什么原因导致占比过高。比如前端我们可以看ITLB 事件和ICache相关的指标,后端是数据相关的,可以看一些和系统内存相关的事件。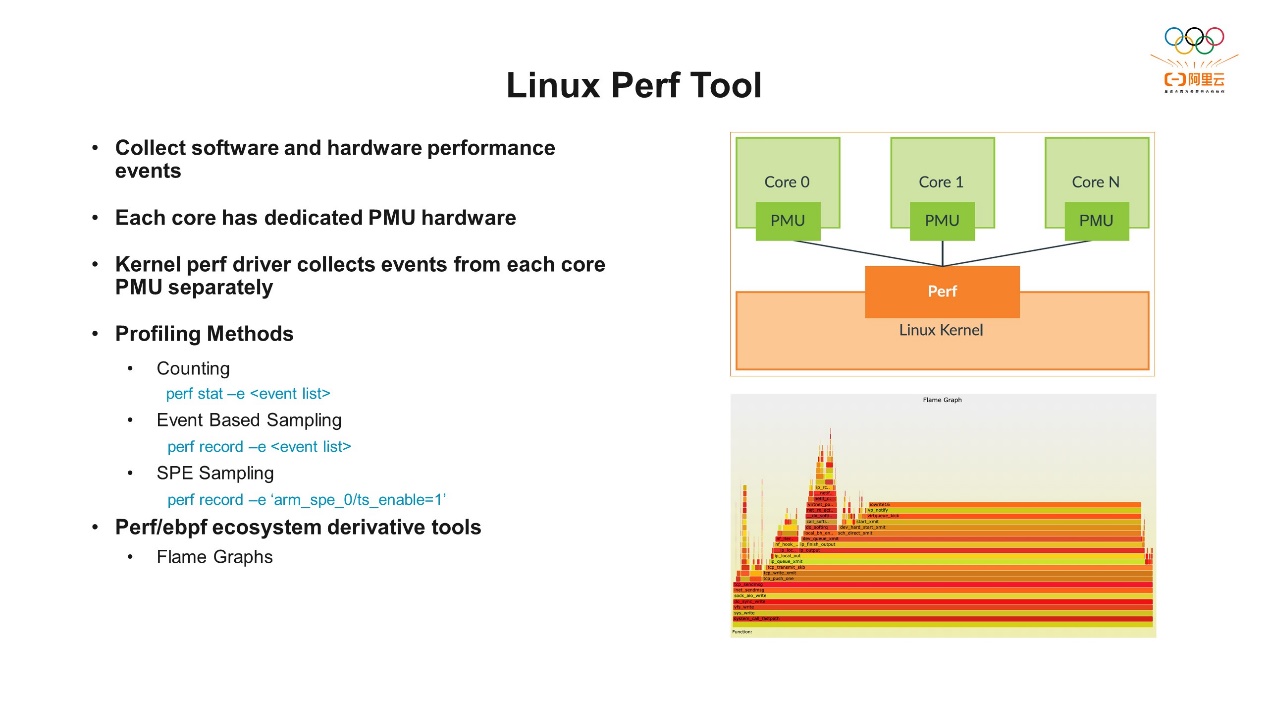 我们有了这些分析方法,还需要相关的工具。接下来简单介绍一下Linux Perf,它是一个使用非常广泛的开源工具。它用来收集PMU的事件,Linux内核里面有一个叫Perf事件的子系统,这个子系统可以捕捉来自不同来源的性能事件,包括软件的事件,也包括处理器的硬件的性能事件。PMU所产生的事件都可以通过它捕捉到。从上图可以看到,每个核心里都有一个PMU的硬件,想要捕捉到这些硬件事件,还需要提供相关的驱动。比如Arm Neoverse N2的核心,我们就会提供相关的驱动程序并提交到内核里面,芯片厂商制作自己的芯片之后,也会实现自己PMU相关的驱动并提交到内核中。这样的话在内核层面有了完善的配置和支持之后,Perf才能顺利地采集到相关的事件。Perf的使用也是基于我们之前说的几种方式。计数是perf stat –e加上我们想要收集的事件;采样是perf record –e加上想要收集的事件,这里还可以设置采样的频率等等参数。SPE一会儿我们专门去讲,Perf也可以直接支持。基于Perf还有一些非常实用的衍生工具,便于我们进行性能分析。比如火焰图,它是一种可视化的性能分析工具,通常它可以和Perf结合使用。火焰图层级的结构的方式展示的函数的调用关系,每一个长条代表一个函数,宽度代表函数在执行期间占总执行时间的占比,不同颜色代表不同的函数或者类别。火焰图还有一定的交互性,点击每一个相关的函数,它会提供相关的交互操作,可以放大、缩小、过滤、深入地分析性能数据等等,帮助我们快速直观地定位到性能问题。二、统计分析扩展
我们有了这些分析方法,还需要相关的工具。接下来简单介绍一下Linux Perf,它是一个使用非常广泛的开源工具。它用来收集PMU的事件,Linux内核里面有一个叫Perf事件的子系统,这个子系统可以捕捉来自不同来源的性能事件,包括软件的事件,也包括处理器的硬件的性能事件。PMU所产生的事件都可以通过它捕捉到。从上图可以看到,每个核心里都有一个PMU的硬件,想要捕捉到这些硬件事件,还需要提供相关的驱动。比如Arm Neoverse N2的核心,我们就会提供相关的驱动程序并提交到内核里面,芯片厂商制作自己的芯片之后,也会实现自己PMU相关的驱动并提交到内核中。这样的话在内核层面有了完善的配置和支持之后,Perf才能顺利地采集到相关的事件。Perf的使用也是基于我们之前说的几种方式。计数是perf stat –e加上我们想要收集的事件;采样是perf record –e加上想要收集的事件,这里还可以设置采样的频率等等参数。SPE一会儿我们专门去讲,Perf也可以直接支持。基于Perf还有一些非常实用的衍生工具,便于我们进行性能分析。比如火焰图,它是一种可视化的性能分析工具,通常它可以和Perf结合使用。火焰图层级的结构的方式展示的函数的调用关系,每一个长条代表一个函数,宽度代表函数在执行期间占总执行时间的占比,不同颜色代表不同的函数或者类别。火焰图还有一定的交互性,点击每一个相关的函数,它会提供相关的交互操作,可以放大、缩小、过滤、深入地分析性能数据等等,帮助我们快速直观地定位到性能问题。二、统计分析扩展 统计分析扩展 (Statistical Profiling Extension, SPE) 是Armv8.2架构引入的功能。首先我们为什么需要SPE?刚才我们提到过,计数只是记录事件触发的硬件事件的总数,它并不能知道哪条指令触发了事件。通过采样我们可以大致知道哪一块程序触发了这些事件,但它的准确度会有一定的限制。通常通过采样定位的代码区域比较大,这就导致开发者通过这个信息只能找到一些相关的热点函数。如果想进一步分析函数中哪一行或者哪几行是热点,就很难准确找到了。只能通过上下文的读取做粗略的估计,而且因为采样和解析都是通过中断的来完成的,所以对采样率也有一定限制,太高的频率会导致系统有很大的负担。SPE则是通过硬件的方式直接在流水线上对CPU的指令进行采样,同时还会收集一系列有用的信息,便于后续的分析。因为SPE是直接在硬件流水线上采集,所以性能开销很小。有了这些信息之后,我们就可以方便的进行进一步的代码分析了。
统计分析扩展 (Statistical Profiling Extension, SPE) 是Armv8.2架构引入的功能。首先我们为什么需要SPE?刚才我们提到过,计数只是记录事件触发的硬件事件的总数,它并不能知道哪条指令触发了事件。通过采样我们可以大致知道哪一块程序触发了这些事件,但它的准确度会有一定的限制。通常通过采样定位的代码区域比较大,这就导致开发者通过这个信息只能找到一些相关的热点函数。如果想进一步分析函数中哪一行或者哪几行是热点,就很难准确找到了。只能通过上下文的读取做粗略的估计,而且因为采样和解析都是通过中断的来完成的,所以对采样率也有一定限制,太高的频率会导致系统有很大的负担。SPE则是通过硬件的方式直接在流水线上对CPU的指令进行采样,同时还会收集一系列有用的信息,便于后续的分析。因为SPE是直接在硬件流水线上采集,所以性能开销很小。有了这些信息之后,我们就可以方便的进行进一步的代码分析了。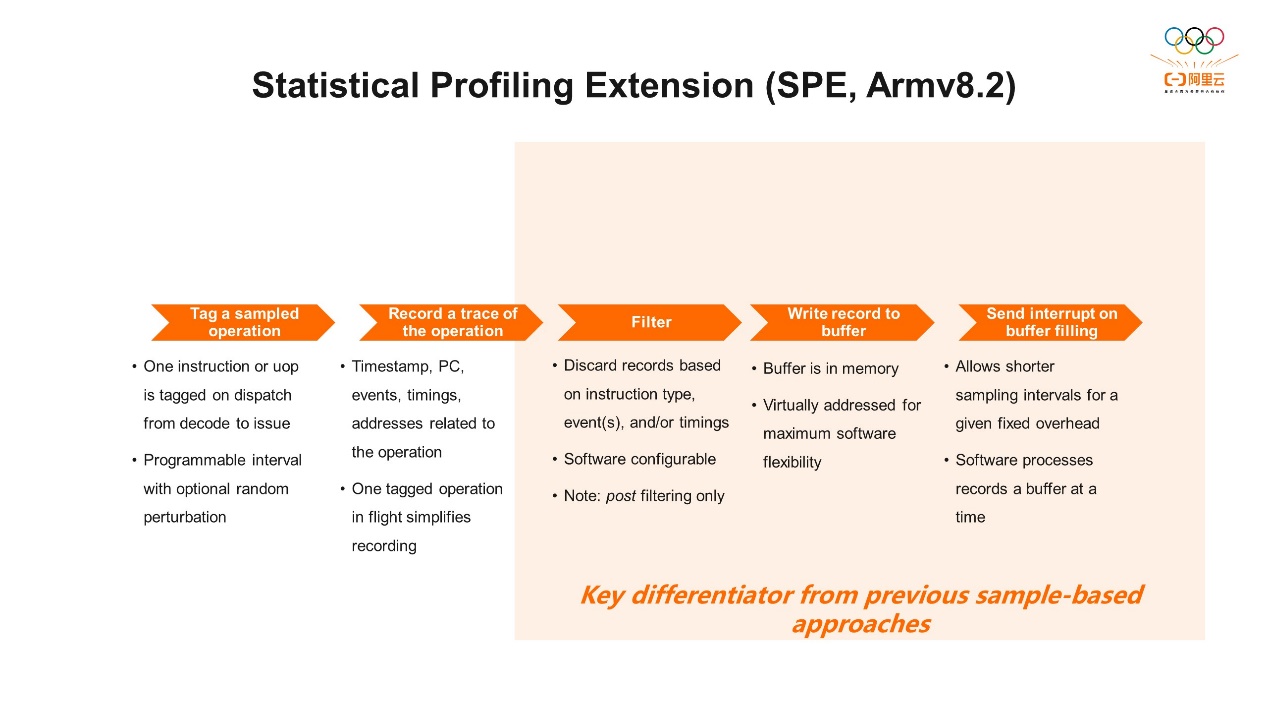 接下来介绍一下SPE采样的过程。通常我们会有一个计数器,每取一条指令,这个计数器就会-1。比如计数器是1000,在流水线每条指令发送之后,计数器就会-1。直到减到零,当前这一条指令就被选择成为要采样的指令。选取了这条指令之后,它在后端执行过程中就会采集一系列的信息,包括时间戳、PC指针、相关的事件、运行的时间,还有和这条指令相关的地址信息都会进行采集。采集信息之后就来到了SPE比较重要的功能——过滤。用户可以根据自己需求过滤掉不需要的指令,根据事件或者执行时间做一下过滤,这些都是通过软件可以做的配置,你可以专注于自己想要收集的指令。这些指令做了过滤之后,就会放到一个存储缓冲区 (memory buffer) 里面,缓冲区满了之后会触发一个软件中断,传回给上层的软件,我们就可以使用Perf工具进行分析。
接下来介绍一下SPE采样的过程。通常我们会有一个计数器,每取一条指令,这个计数器就会-1。比如计数器是1000,在流水线每条指令发送之后,计数器就会-1。直到减到零,当前这一条指令就被选择成为要采样的指令。选取了这条指令之后,它在后端执行过程中就会采集一系列的信息,包括时间戳、PC指针、相关的事件、运行的时间,还有和这条指令相关的地址信息都会进行采集。采集信息之后就来到了SPE比较重要的功能——过滤。用户可以根据自己需求过滤掉不需要的指令,根据事件或者执行时间做一下过滤,这些都是通过软件可以做的配置,你可以专注于自己想要收集的指令。这些指令做了过滤之后,就会放到一个存储缓冲区 (memory buffer) 里面,缓冲区满了之后会触发一个软件中断,传回给上层的软件,我们就可以使用Perf工具进行分析。 刚才提到了过滤,过滤是我们进行分析的一个非常重要的手段。有几个点需要注意一下,我们的过滤并不是在一开始采样的时候就把不感兴趣的采样指令删掉,而是在收集完信息之后往缓冲区里写之前,去过滤掉不需要的指令。我们过滤的条件主要有三种,指令的类型主要包括load、store、branch或者它们的组合。另外一个是指令执行周期数的过滤,比如只采集执行时长小于多少周期的指令,或者相反。还有一个和事件相关的,比如只看缓存缺失相关的,也可以做一定的过滤。举个例子,记录load相关操作的成功退役的指令,并且这些指令的特点是要花费超过100个周期才完成。通过SPE我们可以只采集对性能有影响的指令,方便我们找到相关的热点。
刚才提到了过滤,过滤是我们进行分析的一个非常重要的手段。有几个点需要注意一下,我们的过滤并不是在一开始采样的时候就把不感兴趣的采样指令删掉,而是在收集完信息之后往缓冲区里写之前,去过滤掉不需要的指令。我们过滤的条件主要有三种,指令的类型主要包括load、store、branch或者它们的组合。另外一个是指令执行周期数的过滤,比如只采集执行时长小于多少周期的指令,或者相反。还有一个和事件相关的,比如只看缓存缺失相关的,也可以做一定的过滤。举个例子,记录load相关操作的成功退役的指令,并且这些指令的特点是要花费超过100个周期才完成。通过SPE我们可以只采集对性能有影响的指令,方便我们找到相关的热点。 上图是我们通过Perf收集到的SPE的数据,打开之后可以看到里面会有非常详细的信息,包括PC值、Context packet、相关的事件;RETIRED L1D-ACCESS TLB-ACCESS表示这条指令会触发这么多事件;LAT 51 ISSUE表示从dispatch到issue一共花了51个周期,LAT 55 TOT表示从dispatch到complete,花费了55个周期。此外还包括虚拟地址信息、物理地址信息、数据源等信息。有了这些信息之后,我们可以有针对性地做一些分析。
上图是我们通过Perf收集到的SPE的数据,打开之后可以看到里面会有非常详细的信息,包括PC值、Context packet、相关的事件;RETIRED L1D-ACCESS TLB-ACCESS表示这条指令会触发这么多事件;LAT 51 ISSUE表示从dispatch到issue一共花了51个周期,LAT 55 TOT表示从dispatch到complete,花费了55个周期。此外还包括虚拟地址信息、物理地址信息、数据源等信息。有了这些信息之后,我们可以有针对性地做一些分析。 前面提到了我们可以用Perf直接使用SPE,SPE在Armv8.2引入之后,Armv8.5又做了一些改进,倚天710就是在按Armv8.5这个架构,使用方法是perf record -e arm_spe_0,后面加上我们想要过滤的参数。
前面提到了我们可以用Perf直接使用SPE,SPE在Armv8.2引入之后,Armv8.5又做了一些改进,倚天710就是在按Armv8.5这个架构,使用方法是perf record -e arm_spe_0,后面加上我们想要过滤的参数。 有了SPE之后,我们还可以基于SPE做更多的分析。Perf mem可以获取更详细的内存访问信息,因为SPE包含了数据源信息,就可以知道在访问内存数据的时候是从哪一级访问的。从上图下侧的数据可以看到,我们收集了一些数据,我们只看L1D相关的事件里产生的数据。从Memory access这一栏可以看到,出现L1D缺失之后,它访问了哪些内存,比如5.17%是访问远程缓存,还有直接内存hit到的,还可以从代码层面找到哪些地方导致L1D缺失。
有了SPE之后,我们还可以基于SPE做更多的分析。Perf mem可以获取更详细的内存访问信息,因为SPE包含了数据源信息,就可以知道在访问内存数据的时候是从哪一级访问的。从上图下侧的数据可以看到,我们收集了一些数据,我们只看L1D相关的事件里产生的数据。从Memory access这一栏可以看到,出现L1D缺失之后,它访问了哪些内存,比如5.17%是访问远程缓存,还有直接内存hit到的,还可以从代码层面找到哪些地方导致L1D缺失。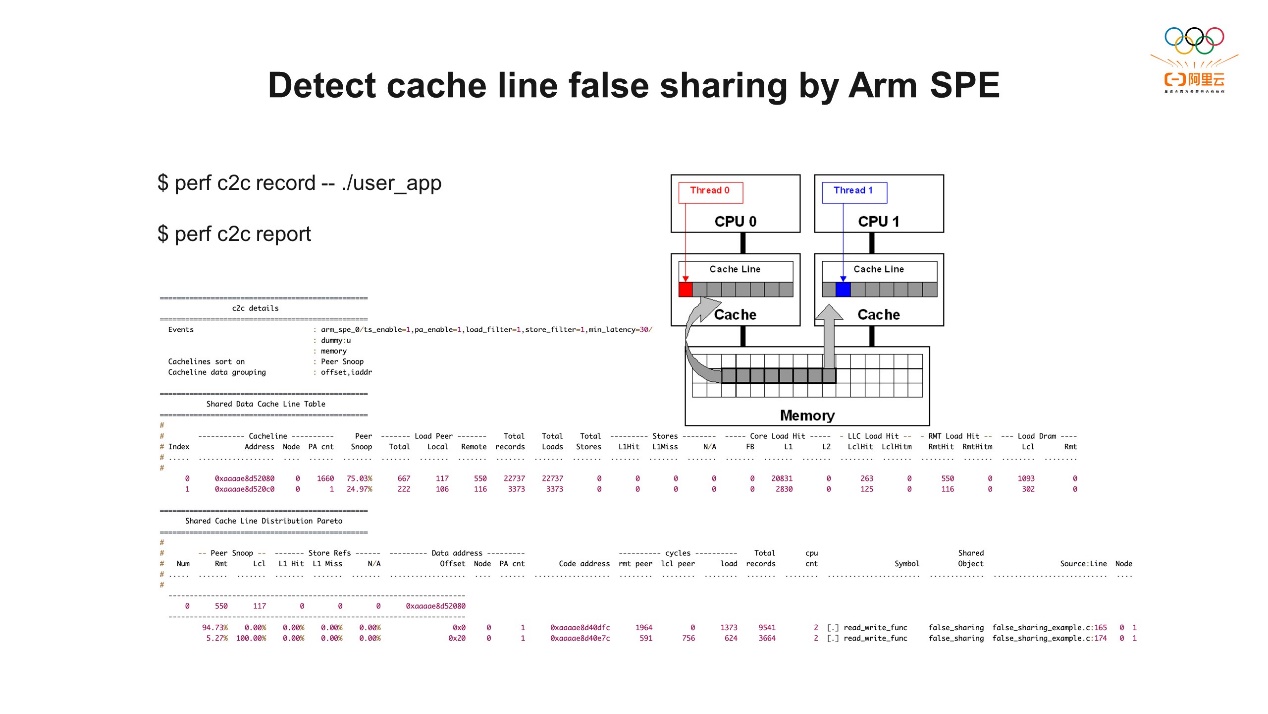 我们还可以通过SPE检测是否出现了伪共享 (false sharing) 场景。当我们有多个核心的时候,如果多个核心同时读写同一个内存的地址,需要通过缓存的硬件机制来完成一致性,这样会产生很多额外的开销。所以我们一般会避免这种现象,但当多个核心同时读写到不同地址的时候,虽然它是不同地址,但地址离得比较近,比如它们被映射到同一个缓存行 (Cache line) 里边。这两个虽然不是同一个地址,但它们在同一个缓存行里被取到了内存里面。而两个不同的核心又同时访问,就会出现隐式的共享行为,我们称之为伪共享。在有了SPE之后,就可以通过perf c2c这条指令收集信息。perf c2c report就可以帮我们检测到是否出现这一场景,发现之后就可以针对相关代码进行改进。如上图中看到的结果,首先可以看到Snoop,它代表出现伪共享的结果,有75%是这条地址产生的。我们进一步看到,这里面有97%由于这段代码导致了伪共享,下一步就可以针对这段代码进行改进,来避免这种现象出现,导致出现额外的性能开销。三、Arm性能分析工具
我们还可以通过SPE检测是否出现了伪共享 (false sharing) 场景。当我们有多个核心的时候,如果多个核心同时读写同一个内存的地址,需要通过缓存的硬件机制来完成一致性,这样会产生很多额外的开销。所以我们一般会避免这种现象,但当多个核心同时读写到不同地址的时候,虽然它是不同地址,但地址离得比较近,比如它们被映射到同一个缓存行 (Cache line) 里边。这两个虽然不是同一个地址,但它们在同一个缓存行里被取到了内存里面。而两个不同的核心又同时访问,就会出现隐式的共享行为,我们称之为伪共享。在有了SPE之后,就可以通过perf c2c这条指令收集信息。perf c2c report就可以帮我们检测到是否出现这一场景,发现之后就可以针对相关代码进行改进。如上图中看到的结果,首先可以看到Snoop,它代表出现伪共享的结果,有75%是这条地址产生的。我们进一步看到,这里面有97%由于这段代码导致了伪共享,下一步就可以针对这段代码进行改进,来避免这种现象出现,导致出现额外的性能开销。三、Arm性能分析工具 前面我们介绍了SPE的基本的概念和使用。下面和大家分享一下Arm平台上常用的两个性能分析工具。第一个工具是Forge MAP。它是由Linaro提供的工具,Linaro是一个会员制的组织,它的目标是为Arm生态合作伙伴提供一个协作平台,减少资源浪费,大家可以一起共同维护底层基础或者软件工具链的开发工作。Forge里面包含三个工具,DDT用来做debug,Map用来做性能分析,Performance report用来生成性能数据的报告。今天我们主要介绍Forge MAP,它通过图形化的方式让用户更好地理解MPI、CPU、IO等行为,以时间线的方式显示程序运行过程中CPU的硬件事件统计,同时还可以关联到源代码,让开发者快速找到导致CPU出现瓶颈的代码段。
前面我们介绍了SPE的基本的概念和使用。下面和大家分享一下Arm平台上常用的两个性能分析工具。第一个工具是Forge MAP。它是由Linaro提供的工具,Linaro是一个会员制的组织,它的目标是为Arm生态合作伙伴提供一个协作平台,减少资源浪费,大家可以一起共同维护底层基础或者软件工具链的开发工作。Forge里面包含三个工具,DDT用来做debug,Map用来做性能分析,Performance report用来生成性能数据的报告。今天我们主要介绍Forge MAP,它通过图形化的方式让用户更好地理解MPI、CPU、IO等行为,以时间线的方式显示程序运行过程中CPU的硬件事件统计,同时还可以关联到源代码,让开发者快速找到导致CPU出现瓶颈的代码段。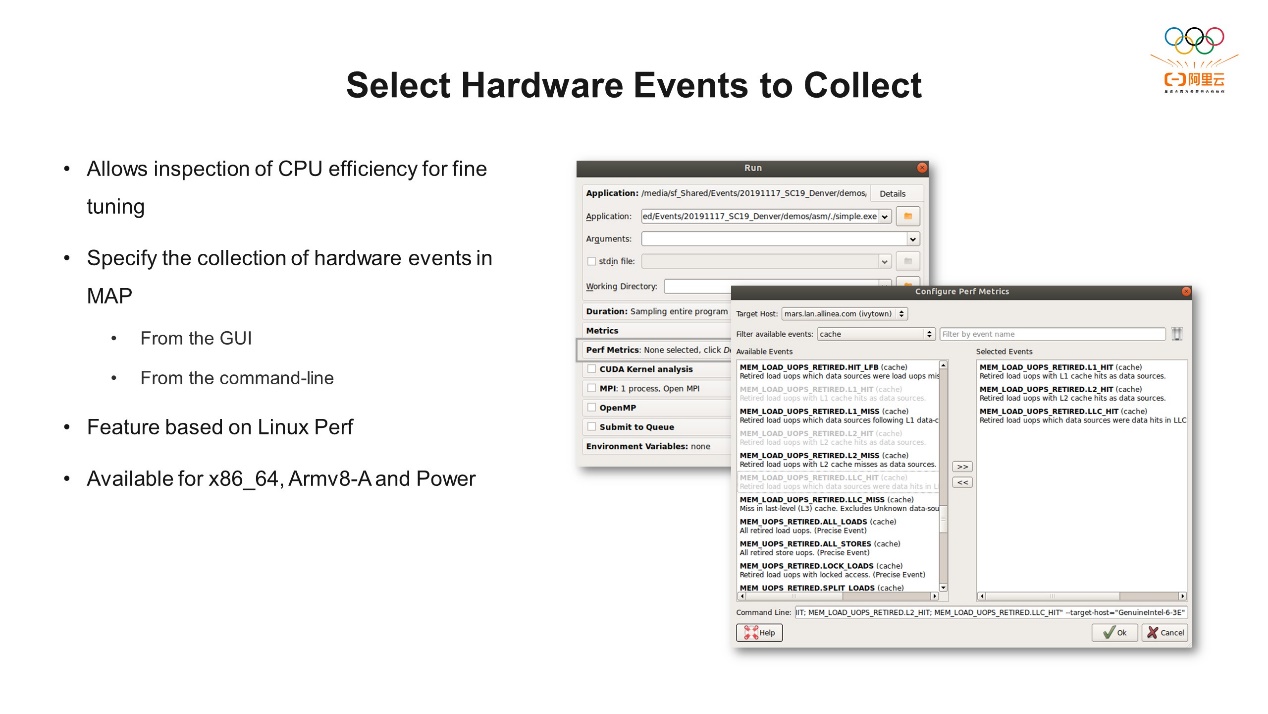 Forge MAP可以通过图形界面的方式选择需要监控的事件。收集收据后它会生成一个静态的数据文件,我们可以把它加载进来,然后对这一段数据进行分析。而且Forge还支持多平台,包括Arm、x86以及PowerPC。
Forge MAP可以通过图形界面的方式选择需要监控的事件。收集收据后它会生成一个静态的数据文件,我们可以把它加载进来,然后对这一段数据进行分析。而且Forge还支持多平台,包括Arm、x86以及PowerPC。 上图是一个针对Redis的例子。可以通过命令行直接收集事件,也可以通过图形界面选择事件。收集之后就会生成一个数据文件,然后把文件加载进来,就可以看到Redis运行过程中关注的事件、相关的指标。Forge使用的时候需要授权许可,感兴趣的朋友可以去Forge主页上下载试用版。
上图是一个针对Redis的例子。可以通过命令行直接收集事件,也可以通过图形界面选择事件。收集之后就会生成一个数据文件,然后把文件加载进来,就可以看到Redis运行过程中关注的事件、相关的指标。Forge使用的时候需要授权许可,感兴趣的朋友可以去Forge主页上下载试用版。 第二个工具是Telemetry Solution。这是Arm推出的一个基于Top-Down进行性能分析的开源工具。前面提到了Top-Down分为第一阶段和第二阶段。第一阶段是四个倾向性的分析,针对每个倾向性,在微架构层面对其他的指标进行进一步分析。上图是针对Telemetry Solution的详细说明。可以通过上图中网址把它下载到Arm服务器上使用。
第二个工具是Telemetry Solution。这是Arm推出的一个基于Top-Down进行性能分析的开源工具。前面提到了Top-Down分为第一阶段和第二阶段。第一阶段是四个倾向性的分析,针对每个倾向性,在微架构层面对其他的指标进行进一步分析。上图是针对Telemetry Solution的详细说明。可以通过上图中网址把它下载到Arm服务器上使用。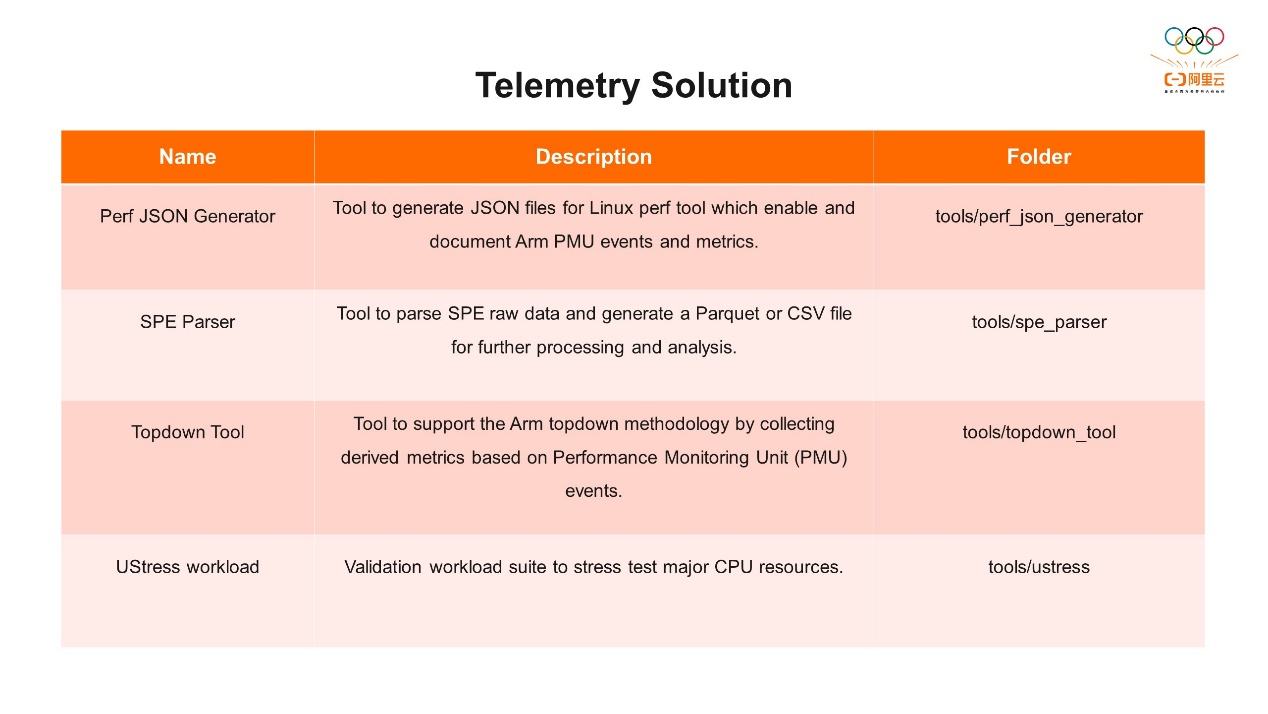 Telemetry Solution包括四个工具,我们主要使用的是Top-Down工具,通过一条简单的命令就可以帮我们收集和Top-Down分析方式相关的指标、数据。另外,它还有JSON Generator,可以针对Arm的PMU生成相关的JSON文件。还有SPE的解析器,通过这个解析器可以把SPE的原始数据解析并导入到CSV的文件里面,方便我们读取和分析。另外我们还提供了一套用于测试微架构性能的工具叫UStress workload,它有一系列的测试用例,可以分析微架构的性能表现。
Telemetry Solution包括四个工具,我们主要使用的是Top-Down工具,通过一条简单的命令就可以帮我们收集和Top-Down分析方式相关的指标、数据。另外,它还有JSON Generator,可以针对Arm的PMU生成相关的JSON文件。还有SPE的解析器,通过这个解析器可以把SPE的原始数据解析并导入到CSV的文件里面,方便我们读取和分析。另外我们还提供了一套用于测试微架构性能的工具叫UStress workload,它有一系列的测试用例,可以分析微架构的性能表现。 我们主要介绍一下使用Top-Down工具的方法,可以直接运行topdown-tool加执行程序,或者把相关的程序启动起来后运行topdown-tool,它会自动收集相关的信息。也可以指定CPU,比如我们在倚天上就可以通过–cpu neoverse-n2指定,也可以把收集到的数据直接导入到CSV文件里,方便后面分析。运行完之后,相关的指标会直接打印出来,上图例子中后端stall占了42.59%,前端stall占0.02%。
我们主要介绍一下使用Top-Down工具的方法,可以直接运行topdown-tool加执行程序,或者把相关的程序启动起来后运行topdown-tool,它会自动收集相关的信息。也可以指定CPU,比如我们在倚天上就可以通过–cpu neoverse-n2指定,也可以把收集到的数据直接导入到CSV文件里,方便后面分析。运行完之后,相关的指标会直接打印出来,上图例子中后端stall占了42.59%,前端stall占0.02%。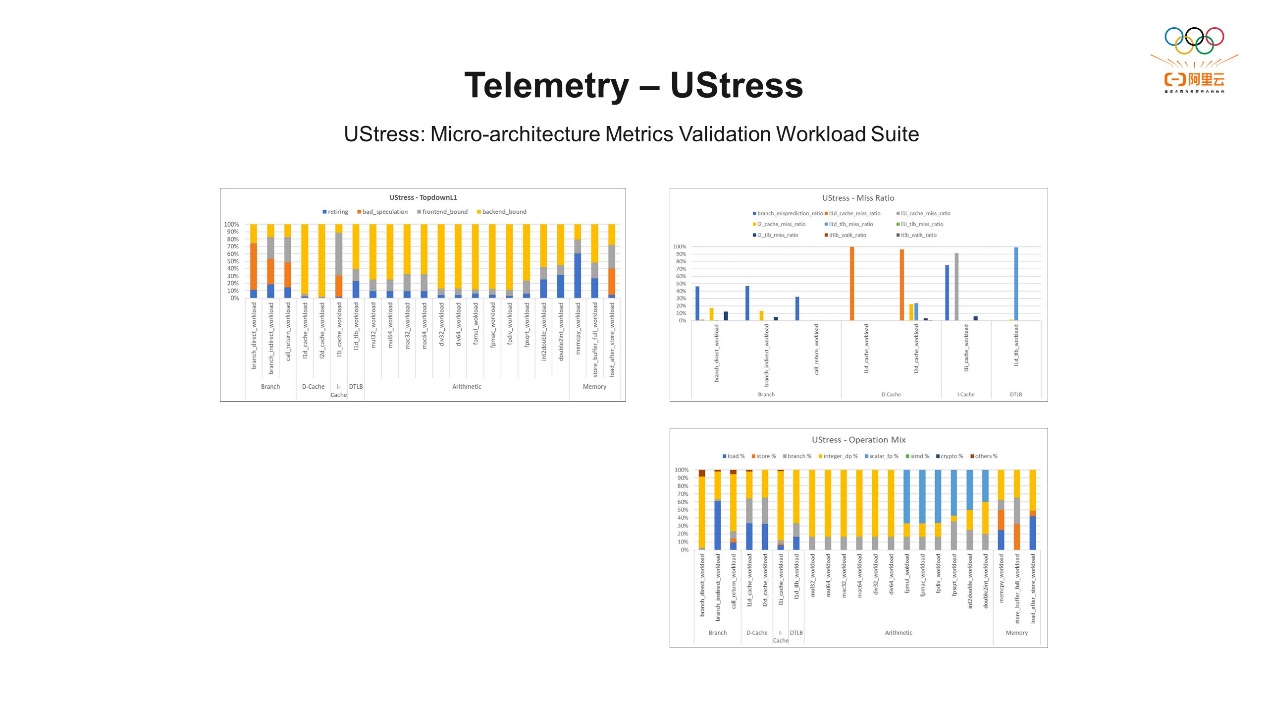 UStress是微架构层面的工作负载的验证套件。这里有很多相关的套件,比如针对L1ICache的工作负载,L1DCache的工作负载测试的。通过topdown-tool可以看到每个工作负载的前端、后端占比,便于我们理解CPU微架构层面的问题。四、优化案例
UStress是微架构层面的工作负载的验证套件。这里有很多相关的套件,比如针对L1ICache的工作负载,L1DCache的工作负载测试的。通过topdown-tool可以看到每个工作负载的前端、后端占比,便于我们理解CPU微架构层面的问题。四、优化案例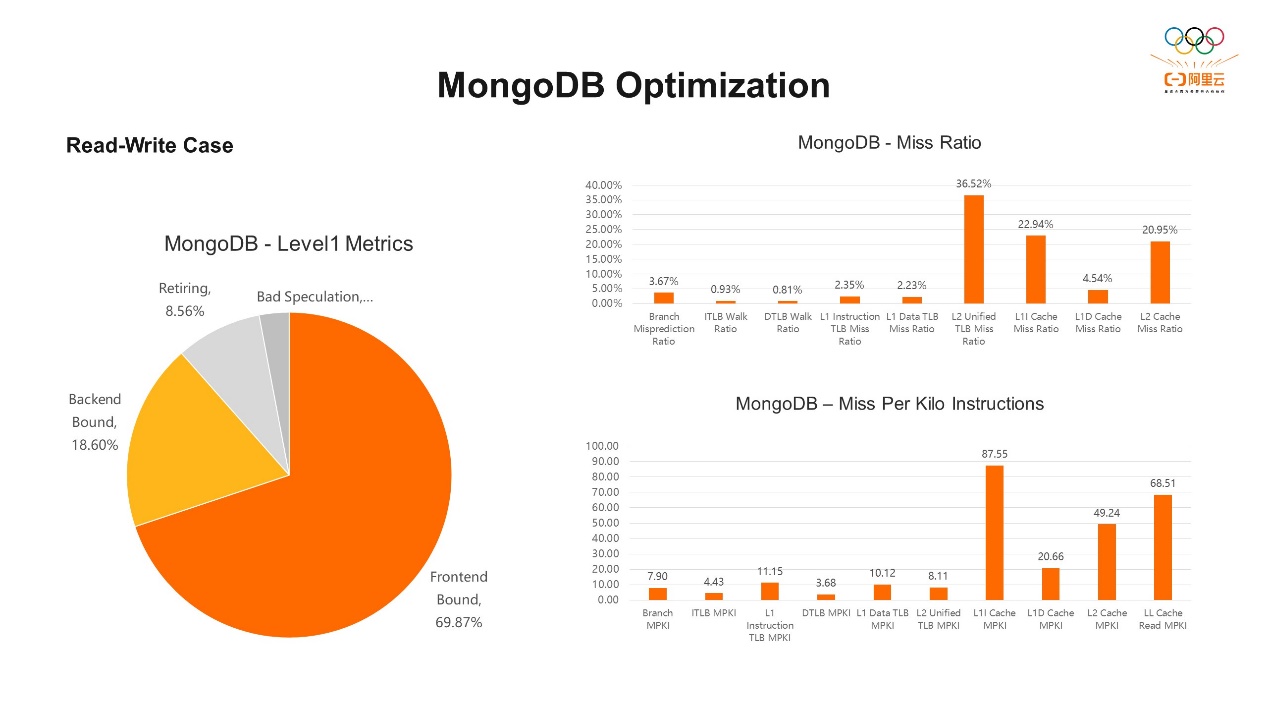 第一个例子,MongoDB的优化。MongoDB是一款开源的、NoSQL的数据库,支持灵活的数据模型,可以存储各种数据类型,无需预定义模式。它比较适用于大规模和高性能的应用程序,是现在比较流行的数据库选择,也是各种项目的理想数据库解决方案。这次优化主要针对读写混合的案例,我们在MongoDB运行期间先通过topdown-tool收集收据,可以明显的看到它的前端Bound占比约高达70%。有了一个总体的指标之后,可以细粒度地看其他指标。从“MongoDB – Miss Ratio”中可以看到,L2 Unified TLB Miss Ratio的占比较高,有36.52%。刚才我们提到L2的TLB前端和后端都会使用。其次是L1I Cache Miss Ratio,占了22.94%,然后是L2 Cache Miss Ratio,占了20.95%。由此我们可以看到,主要集中在前端。前端的优化方式一般是ICache和ITLB这两个相关的资源会对前端影响比较大,针对它们我们可以有几种优化方式。
第一个例子,MongoDB的优化。MongoDB是一款开源的、NoSQL的数据库,支持灵活的数据模型,可以存储各种数据类型,无需预定义模式。它比较适用于大规模和高性能的应用程序,是现在比较流行的数据库选择,也是各种项目的理想数据库解决方案。这次优化主要针对读写混合的案例,我们在MongoDB运行期间先通过topdown-tool收集收据,可以明显的看到它的前端Bound占比约高达70%。有了一个总体的指标之后,可以细粒度地看其他指标。从“MongoDB – Miss Ratio”中可以看到,L2 Unified TLB Miss Ratio的占比较高,有36.52%。刚才我们提到L2的TLB前端和后端都会使用。其次是L1I Cache Miss Ratio,占了22.94%,然后是L2 Cache Miss Ratio,占了20.95%。由此我们可以看到,主要集中在前端。前端的优化方式一般是ICache和ITLB这两个相关的资源会对前端影响比较大,针对它们我们可以有几种优化方式。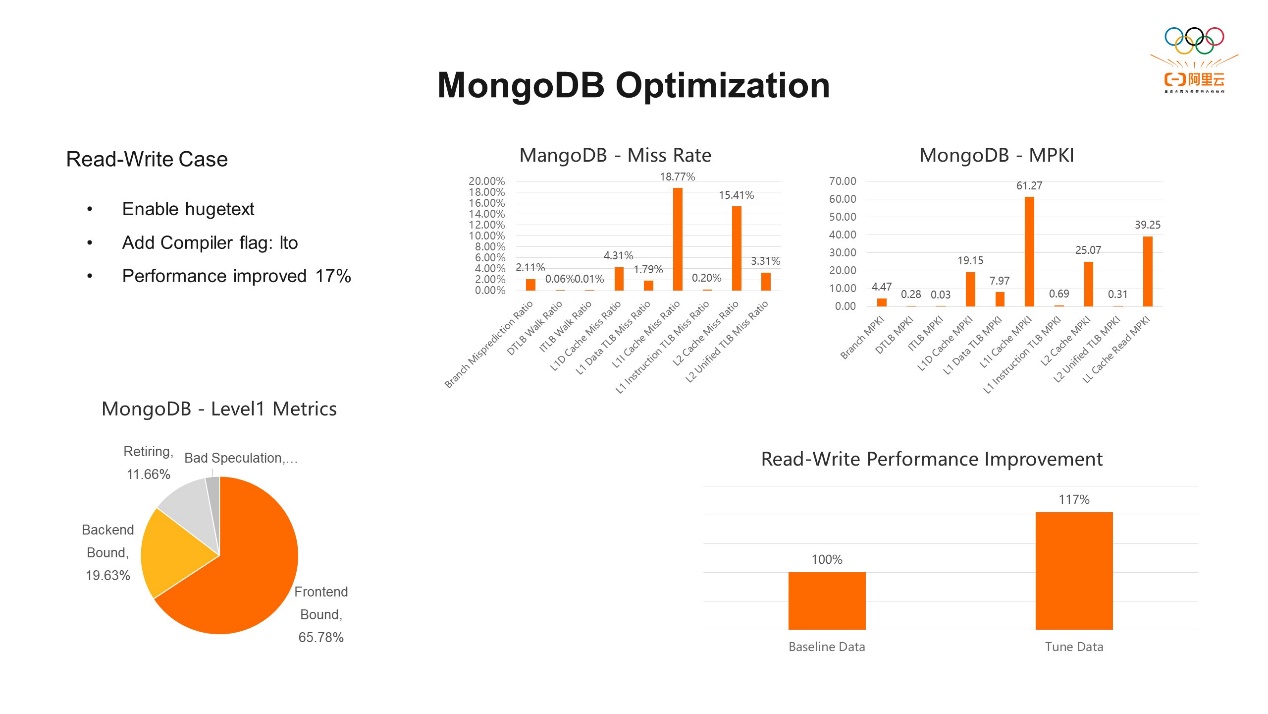 第一种是代码段大页。大页技术是我们操作系统中优化内存访问延迟的一种比较常用的技术,主要优化了TLB缺失,常用的大页技术包括透明大页和和全局大页。在一些合适的场合,性能的提升有时候能达到10%以上,尤其现在云上的应用对内存的使用需求比较大,所以大页技术是现在我们提升性能比较常用的一种优化手段。透明大页是内核很早就支持了,它可以避免多次的缺页产生的开销,更深层次的是它优化了TLB缺失产生的开销。但过去的大页主要是针对运行过程中分配的内存进行优化,更多作用在后端。目前,阿里的AliLinux、龙蜥操作系统都原生支持代码段大页。代码大页在透明大页的基础上,将支持扩展到可执行二进制文件,包括进程二进制文件本身、共享库等可执行数据,这些用上透明大页。从而可以显著降低减少ITLB缺失。另外一个针对前端的优化手段是是用编译选项lto。lto主要的优势在于代码的优化,特别是在函数内联、函数重排等方面,以及在整个程序的链接阶段进行全局优化。Ito的优化可以让代码更紧凑,减少函数的调用,从而改善指令和数据局部性,间接减少指令内存的访问时延,从而减少ITLB缺失。另外因为程序指令得到了更优的排列,提高缓存的命中率,有助于降低ITLB缺失和ICache缺失。接下来看一看把这两个优化选项加进之后,性能是否有一定优化呢?通过Top-Down我们可以看到,前端从原来的近70%降到了65.78%,虽然占比还是比较高,但相关的指标降低了很多。L2 TLB缺失从原来的36.52%直接降到3.31%,这是一个比较明显的降幅。L1I的TLB缺失从原来的2.35%降到了0.2%。前端指令运行的效率也明显提升了,还有L1I Cache缺失从原来的约23%也降到了18%左右。所以整体上前端相关的指标都有一定的下降,最终我们看它的读写的性能提升了17%。
第一种是代码段大页。大页技术是我们操作系统中优化内存访问延迟的一种比较常用的技术,主要优化了TLB缺失,常用的大页技术包括透明大页和和全局大页。在一些合适的场合,性能的提升有时候能达到10%以上,尤其现在云上的应用对内存的使用需求比较大,所以大页技术是现在我们提升性能比较常用的一种优化手段。透明大页是内核很早就支持了,它可以避免多次的缺页产生的开销,更深层次的是它优化了TLB缺失产生的开销。但过去的大页主要是针对运行过程中分配的内存进行优化,更多作用在后端。目前,阿里的AliLinux、龙蜥操作系统都原生支持代码段大页。代码大页在透明大页的基础上,将支持扩展到可执行二进制文件,包括进程二进制文件本身、共享库等可执行数据,这些用上透明大页。从而可以显著降低减少ITLB缺失。另外一个针对前端的优化手段是是用编译选项lto。lto主要的优势在于代码的优化,特别是在函数内联、函数重排等方面,以及在整个程序的链接阶段进行全局优化。Ito的优化可以让代码更紧凑,减少函数的调用,从而改善指令和数据局部性,间接减少指令内存的访问时延,从而减少ITLB缺失。另外因为程序指令得到了更优的排列,提高缓存的命中率,有助于降低ITLB缺失和ICache缺失。接下来看一看把这两个优化选项加进之后,性能是否有一定优化呢?通过Top-Down我们可以看到,前端从原来的近70%降到了65.78%,虽然占比还是比较高,但相关的指标降低了很多。L2 TLB缺失从原来的36.52%直接降到3.31%,这是一个比较明显的降幅。L1I的TLB缺失从原来的2.35%降到了0.2%。前端指令运行的效率也明显提升了,还有L1I Cache缺失从原来的约23%也降到了18%左右。所以整体上前端相关的指标都有一定的下降,最终我们看它的读写的性能提升了17%。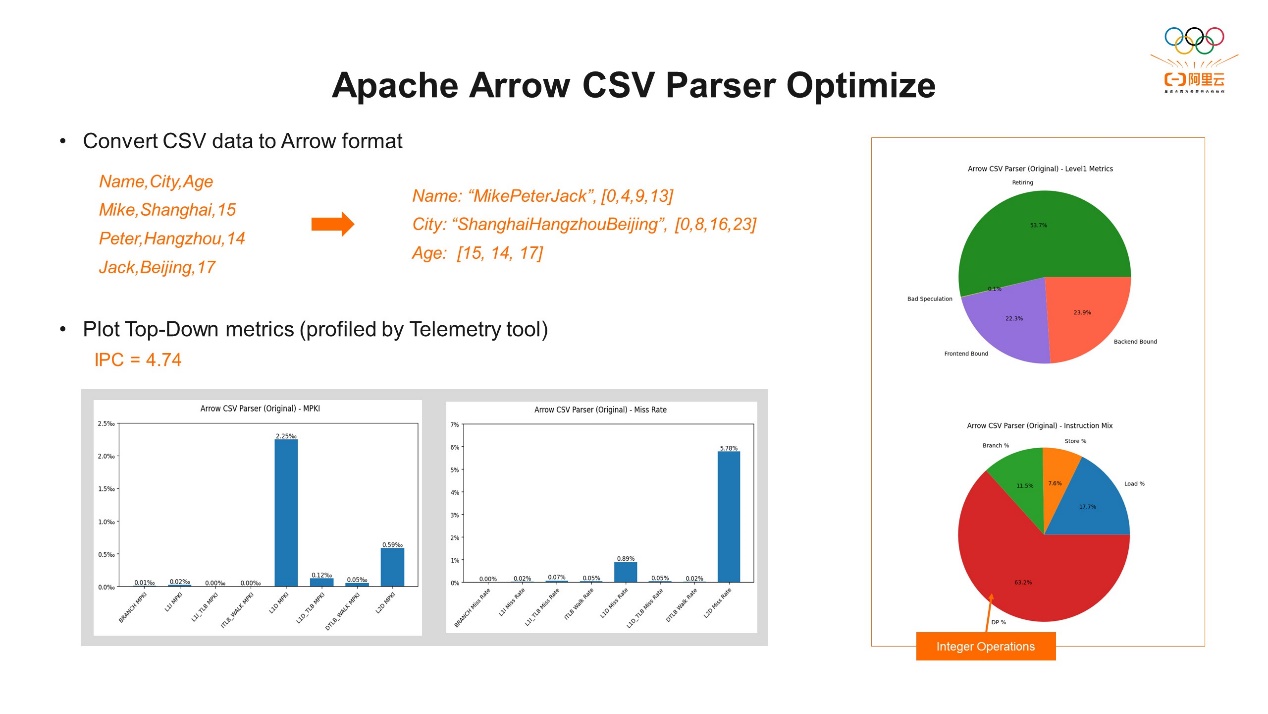 第二个例子,是针对Apache Arrow下做了两个优化。Apache Arrow是Apache基金会的一个项目,目前作为一种跨平台的数据层来加快大数据分析项目的运行速度。它的特点是使用列式存储的方式存储数据,即将相同字段的数据集中排在一起,方便快速查询,比传统的行式存储更高效。首先针对CSV的解析做了优化。CSV本身是行式存储,要把它转换成Arrow支持的结构需要做一个转换。上图例子中第一行是属性,包括姓名、城市、年龄,转换之后姓名会把所有相关的姓名放在一起,后面会有一个对应的偏移量,便于我们查找,这就是整个转换过程。通过topdown-tool看到退役的指令超过50%,前端后端也比较平衡,相关的数据都不高,是不是没有优化空间了呢?我们可以再看一下另一个指标,退役的指令类型的占比,DP的占比超过60%,DP就是整数相关的操作指令。那么整数的操作指令为什么会多呢?我们还要对它的CSV的转换机制做一个简单分析。
第二个例子,是针对Apache Arrow下做了两个优化。Apache Arrow是Apache基金会的一个项目,目前作为一种跨平台的数据层来加快大数据分析项目的运行速度。它的特点是使用列式存储的方式存储数据,即将相同字段的数据集中排在一起,方便快速查询,比传统的行式存储更高效。首先针对CSV的解析做了优化。CSV本身是行式存储,要把它转换成Arrow支持的结构需要做一个转换。上图例子中第一行是属性,包括姓名、城市、年龄,转换之后姓名会把所有相关的姓名放在一起,后面会有一个对应的偏移量,便于我们查找,这就是整个转换过程。通过topdown-tool看到退役的指令超过50%,前端后端也比较平衡,相关的数据都不高,是不是没有优化空间了呢?我们可以再看一下另一个指标,退役的指令类型的占比,DP的占比超过60%,DP就是整数相关的操作指令。那么整数的操作指令为什么会多呢?我们还要对它的CSV的转换机制做一个简单分析。 CSV的结构的存储格式依赖于几个特殊字符,包括逗号、回车换行、双引号等等。所以我们在做转换的时候,土法炼钢的方法就是逐个字节对比,碰到特殊字符就做相应的操作。比如逗号,我知道前面是一个数据,把它取出来换行是下一组数据,当然这种方法的性能肯定非常差。现在Arrow里面的实现方式是每八个字节取一次,取八个之后,我们先判断一下这八个字节里是否有特殊字符。如果有我们就进入到slow path再逐个对比。如果没有,就直接把这八个字节整体取过来,这样可以提高转换效率。那么我们如何判断这八个字节里是否有特殊字符呢?Arrow里用了布隆过滤器 (Bloom Filter) 的算法,它通过字节的相与或操作来快速判断,这是一种比较高效的算法。但因为这个算法做了很多与或操作,这些操作是我们看到整数指令,DP占比60%的原因就主要来自于这里。针对这类指令,通常的优化的手段是用并行计算指令进行优化。
CSV的结构的存储格式依赖于几个特殊字符,包括逗号、回车换行、双引号等等。所以我们在做转换的时候,土法炼钢的方法就是逐个字节对比,碰到特殊字符就做相应的操作。比如逗号,我知道前面是一个数据,把它取出来换行是下一组数据,当然这种方法的性能肯定非常差。现在Arrow里面的实现方式是每八个字节取一次,取八个之后,我们先判断一下这八个字节里是否有特殊字符。如果有我们就进入到slow path再逐个对比。如果没有,就直接把这八个字节整体取过来,这样可以提高转换效率。那么我们如何判断这八个字节里是否有特殊字符呢?Arrow里用了布隆过滤器 (Bloom Filter) 的算法,它通过字节的相与或操作来快速判断,这是一种比较高效的算法。但因为这个算法做了很多与或操作,这些操作是我们看到整数指令,DP占比60%的原因就主要来自于这里。针对这类指令,通常的优化的手段是用并行计算指令进行优化。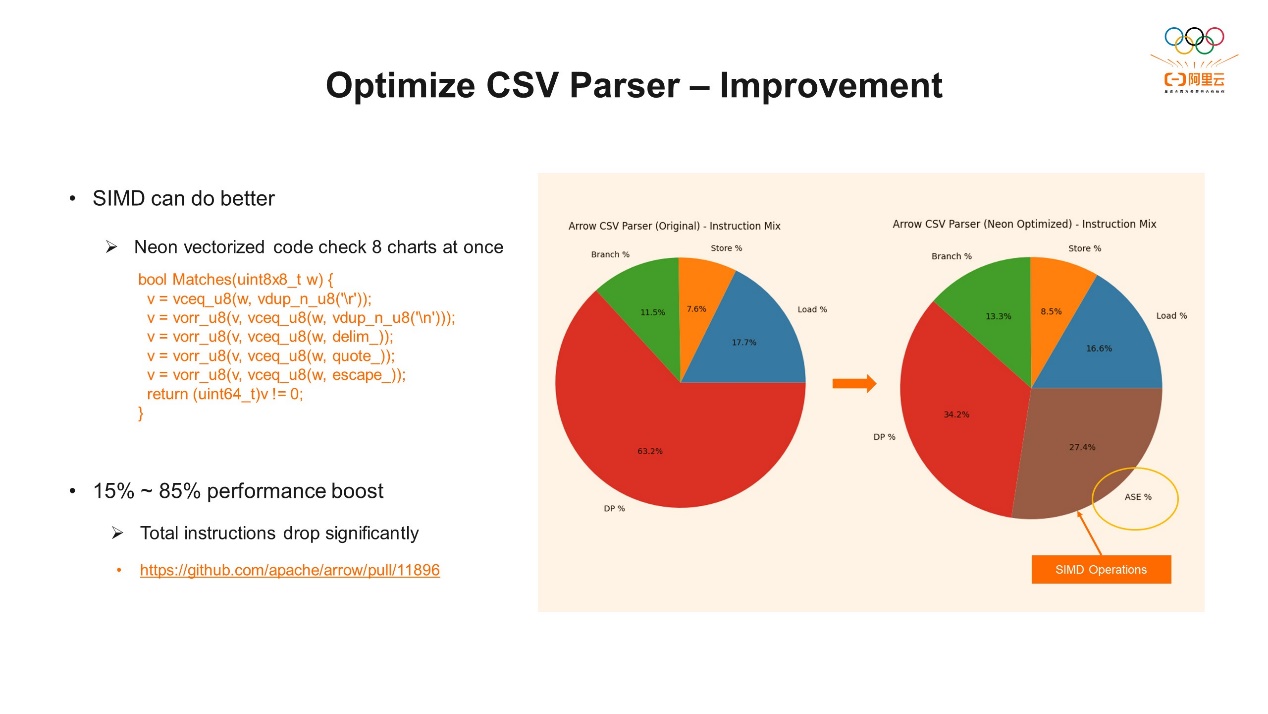 现在大部分CPU都支持并行计算,Arm Neon™ 指令可以同时检查这八个字符,不需要逐个对比,也不需要任何算法,一条Neon指令直接判断这八个里面是否有特殊的字符。优化之后,我们可以看到,原来超过60%的DP占比降到了30%左右,性能提升了15%到85%,这取决于CSV文件的格式和数据量的大小。
现在大部分CPU都支持并行计算,Arm Neon™ 指令可以同时检查这八个字符,不需要逐个对比,也不需要任何算法,一条Neon指令直接判断这八个里面是否有特殊的字符。优化之后,我们可以看到,原来超过60%的DP占比降到了30%左右,性能提升了15%到85%,这取决于CSV文件的格式和数据量的大小。 下一个是一个反向操作,Arrow存好的数据还要转回CSV格式。这个过程要比之前简单,因为我们有数据,有相关的偏移量,直接按照偏移量就可以把数据提取出来。但是在做Top-Down分析的时候发现,它有超过20%的Branch的相关指令,而且有4%的Miss Ratio。分支预测似乎是有一些问题,需要做进一步分析。
下一个是一个反向操作,Arrow存好的数据还要转回CSV格式。这个过程要比之前简单,因为我们有数据,有相关的偏移量,直接按照偏移量就可以把数据提取出来。但是在做Top-Down分析的时候发现,它有超过20%的Branch的相关指令,而且有4%的Miss Ratio。分支预测似乎是有一些问题,需要做进一步分析。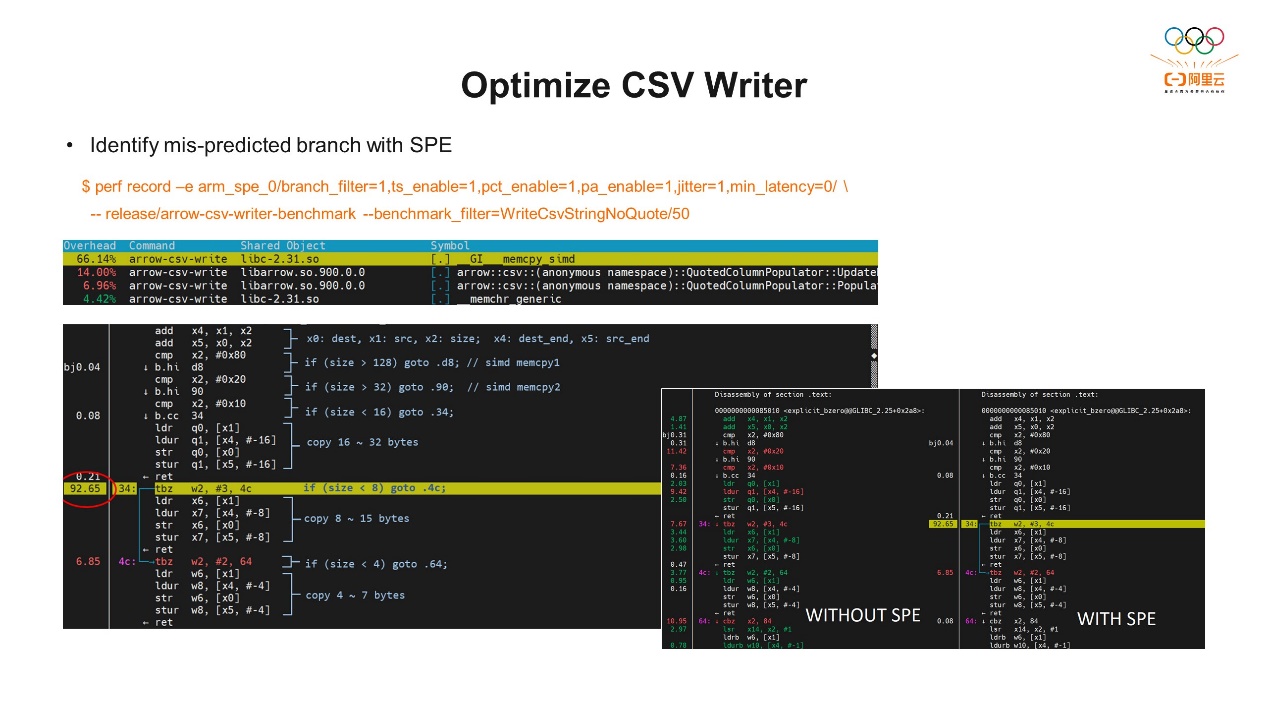 我们通过SPE做了一些分析,因为SPE可以看到Branch相关的指令操作,而且它的准确度很高。普通方法很难在代码里很精确的找到分支预测失败的关键代码段,使用SPE就可以很精确的找到。上图可以看到,memcpy占比有66%左右,memcpy是glibc的一个标准函数,我们通常调用它来做内存的数据的拷贝。但要注意一下,这里的66%并不全是错误的分支预测,而是说错误的分支预测中有66%来自于memcpy。从上图还可以看到,size=8这个地方,失败率是最高的。同样,92%是指所有分支预测失败的里面有92%是在这里失败了。我们通过右侧对比图可以看到,如果不用SPE,使用传统方式热点的分布是非常的散的。使用SPE后,可以精确的找到是哪一条代码导致了大量分支预测失败,针对这个代码我们就可以做进一步的分析和优化了。
我们通过SPE做了一些分析,因为SPE可以看到Branch相关的指令操作,而且它的准确度很高。普通方法很难在代码里很精确的找到分支预测失败的关键代码段,使用SPE就可以很精确的找到。上图可以看到,memcpy占比有66%左右,memcpy是glibc的一个标准函数,我们通常调用它来做内存的数据的拷贝。但要注意一下,这里的66%并不全是错误的分支预测,而是说错误的分支预测中有66%来自于memcpy。从上图还可以看到,size=8这个地方,失败率是最高的。同样,92%是指所有分支预测失败的里面有92%是在这里失败了。我们通过右侧对比图可以看到,如果不用SPE,使用传统方式热点的分布是非常的散的。使用SPE后,可以精确的找到是哪一条代码导致了大量分支预测失败,针对这个代码我们就可以做进一步的分析和优化了。 我们需要分析一下为什么使用memcpy会出现这种情况。Memcpy的代码会根据复制的数据大小进行优化,它可以并行地把数据直接拷贝过来。这个时候它会根据输入长度选择并行计算指令使用的位宽,所以才会有很多分支判断。在Arrow里使用了两条memcpy,第一条是把找到的数据拷贝过去,第二条是把特殊字符拷贝过去。我们可以看到刚才最长错误的分支预测是在大小是否等于八的地方做了错误预测。因为第一个数据段的大小一般大于八,而第二个特殊字符是一个或两个,比如逗号、回车换行。所以这两个memcpy不停循环,使得CPU很难做出正确预测。优化方法就是把第二条针对特殊字符的memcpy改成直接按照尺寸的大小(1或2)传入memcpy。因为数据大小已经指定了,在编译的时候,编译器会直接把这段代码优化成一对load和store指令,不需要进入memcpy函数里。优化后性能有20%-50%的提升。原来memcpy的Miss Ratio超过60%,现在只占17%。通过以上两个例子可以让我们直观的感受一下,怎么通过PMU事件,通过Top-Down的方法论做性能的分析和优化。
我们需要分析一下为什么使用memcpy会出现这种情况。Memcpy的代码会根据复制的数据大小进行优化,它可以并行地把数据直接拷贝过来。这个时候它会根据输入长度选择并行计算指令使用的位宽,所以才会有很多分支判断。在Arrow里使用了两条memcpy,第一条是把找到的数据拷贝过去,第二条是把特殊字符拷贝过去。我们可以看到刚才最长错误的分支预测是在大小是否等于八的地方做了错误预测。因为第一个数据段的大小一般大于八,而第二个特殊字符是一个或两个,比如逗号、回车换行。所以这两个memcpy不停循环,使得CPU很难做出正确预测。优化方法就是把第二条针对特殊字符的memcpy改成直接按照尺寸的大小(1或2)传入memcpy。因为数据大小已经指定了,在编译的时候,编译器会直接把这段代码优化成一对load和store指令,不需要进入memcpy函数里。优化后性能有20%-50%的提升。原来memcpy的Miss Ratio超过60%,现在只占17%。通过以上两个例子可以让我们直观的感受一下,怎么通过PMU事件,通过Top-Down的方法论做性能的分析和优化。 上图中罗列了相关的文档,包括Arm Neoverse N1和N2的PMU指南、SPE的介绍和一些工具等等。以上就是我本次课程的全部内容。想要关注更多【倚天实例迁移课程】直播的同学可以点击链接进入活动官网了解更多资讯!
上图中罗列了相关的文档,包括Arm Neoverse N1和N2的PMU指南、SPE的介绍和一些工具等等。以上就是我本次课程的全部内容。想要关注更多【倚天实例迁移课程】直播的同学可以点击链接进入活动官网了解更多资讯!
